Python笔记¶
统计信息:字数 25237 阅读51分钟
原始笔记链接:https://cloud.seatable.cn/dtable/external-links/59b453a8639945478de2/
0111 有没有使用过爬虫?具体的原理是什么¶
个人小项目中使用过简单的 python 爬虫(太极拳排名、静态小说等非登录认证的静态网页,且没有加密)
有一个静态页面的投票网站,我们需要获取不同人员的投票数,然后进行分析,找出最大值,中值,平均值等数据(复杂分析暂时不会)
基本思路:
1、使用 request 库模拟请求,浏览器返回 HTML 结果
2、使用 BS4 库处理爬取的 HTML,把字符串转换数据结构,并找到需要的标签(例如 script li 等)
3、数据处理(求最值,求平均值等),使用 io 模块写入本地的 txt 文件(如果是复杂的文件,可能使用 excel 或者 spss 软件进行数据分析,这是后续的过程)
前端的反思:反爬虫策略
1、增加登录验证,减少对静态界面爬取。
2、使用 canvas img 等复杂元素节点,例如百度文库,这个给爬虫后续处理增加难度。
3、文本编辑时,界面添加很多脏文本,就是不显示在界面上的特殊符号,然后被后端爬取到。或者 HTML 文本先加密,然后 JS 代码进行解密。这个在很多购物网站中使用,例如美团。
# 请求库
import requests
# 解析库
from bs4 import BeautifulSoup
# 用于解决爬取的数据格式化
import io
import sys
# 设置爬取的默认字符编码(这是python2的reload函数,python3应该使用新语法)
reload(sys)
sys.setdefaultencoding('utf8')
# 爬取的网页链接
r= requests.get("http://jsqg.sports.cn/index.php?s=/home/index/index/p/1.html")
# 中文显示
r.encoding='utf-8'
r.encoding=None
result = r.text
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result,'html.parser')
# 具体标签
print("解析后的数据")
# print(bs.span)
a={}
# 获取已爬取内容中的script标签内容
data=bs.find_all('script')
# 获取已爬取内容中的td标签内容
data1=bs.find_all('li')
# 将爬取后的数据写入文件
filename = 'test_text.txt'
with open(filename, 'w') as file_object:
for j in data1:
file_object.write("%s\n" % (j.text))
0150 python 字符串拼接变量语法¶
非重点
默认模板字符串,这样可以很好的说明变量的数据类型(类似C语言写法)
name = 'Mike'
age = 20
print("%s is good, he is %d score" % (name, age))
还有一个 f 字符串(类似JS模板字符串)
print(f"Hello, {first_name} {last_name}")
0205 Python 序列解包¶
序列解包是 python3 的语法糖,可以批量进行复制或者解包
参考链接:https://blog.csdn.net/yilovexing/article/details/80576788
本质上,python 变量存储的不是值,而是内存地址。这个操作是把引用的内存地址直接交换。
# 简单赋值
x, y = 1, 2
# x, y 调换顺序
x, y = y, x
# 斐波那契数列中求和
x, y = y, x + y
# 获取剩余部分(*表示)
x, y, *z = 1, 2, 3, 4, 5 # z [3, 4, 5]
x, *y, z = 1, 2, 3, 4, 5 # y [2, 3, 4]
x, *y, z = 1, 2 # x 是1,z 是2, y是空列表
复杂情况
(a, b), (c, d) = (1, 2), (3, 4)
s = 'ABCDEFG'
while s:
x, *s = s
print(x, s)
# result
A ['B', 'C', 'D', 'E', 'F', 'G', 'H']
B ['C', 'D', 'E', 'F', 'G', 'H']
C ['D', 'E', 'F', 'G', 'H']
D ['E', 'F', 'G', 'H']
E ['F', 'G', 'H']
F ['G', 'H']
G ['H']
H []
0283 python 字符串 strip lstrip rstrip 用法¶
a.strip()
把字符串左右两侧的某个字符串去掉。不传参,默认去掉的是空格和换行符;传参,去掉的是传递的子字符串。
a = ' Hello Blog Mike!'
a.strip()
a.strip('!')
a.lstrip()
a.rstrip()
分别表示从左边和右边去掉特定字符串,加入参数类似效果
a.lstrip()
a.rstrip()
0284 python 字符串 replace 用法¶
str = 'Hello Tony! Hello Mike!'
str.replace('Hello', 'Hi', 1)
第一个参数是需要替换的字符串
第二个参数是新的字符串
第三个参数(可选)是替换的次数,默认是全部替换
0297 python reload 函数¶
reload 函数
作用:重新载入之前载入的模块
参考链接:https://www.runoob.com/python/python-func-reload.html
在 Python2.x 版本中 reload() 是内置函数,可以直接使用,参见 Python2.x reload() 函数。
在 Python2.x ~ Python3.3 版本移到 imp 包中(Python2.x 也可以导入 imp 包使用)。
Python3.4 之后到版本移到了 importlib 包中,实际案例
# 重新载入 sys 模块
import sys
import importlib
importlib.reload(sys)
为什么会重载模块?
Python 模块重载(通常通过 importlib.reload() 函数实现)的需求可能来自几个不同的场景:
-
开发过程中的调试:在开发过程中,经常需要修改模块的代码并立即看到修改后的效果。通过重载模块,你可以避免每次修改后都重新启动整个Python解释器或应用程序。
-
动态配置:在某些情况下,你可能希望根据运行时条件动态地更改模块的行为。虽然这通常可以通过配置文件、环境变量或类的设计来实现,但模块重载提供了一种更直接的方法来更改模块中的代码。
-
插件系统:如果你的应用程序支持插件,并且这些插件是以Python模块的形式提供的,那么你可能需要在运行时加载、卸载和重新加载这些插件。模块重载在这种情况下可能很有用。
-
交互式环境:在Jupyter notebook、IDLE等交互式Python环境中,你可能需要在不退出环境的情况下修改和测试代码。模块重载允许你在这些环境中重新加载模块,而无需重启整个环境。
-
热更新:虽然这在Python中不常见,但在某些情况下,你可能希望在不中断服务的情况下更新正在运行的代码。虽然这通常涉及到更复杂的技术(如代码热替换或进程间通信),但模块重载可能是这种策略的一部分。
然而,需要注意的是,过度依赖模块重载可能会导致代码难以理解和维护。每次你使用 importlib.reload() 时,都应该确保你理解其后果,并考虑是否有更优雅、更可维护的解决方案。
另外,Python 的导入系统,并不是设计来支持频繁的模块重载的。因此,在某些情况下,重载模块可能会导致意外的副作用,如名称空间污染、状态不一致等。因此,在使用模块重载时应该小心。
0298 python 中 self 是什么¶
self 是在为 class 编写 instance method 的时候,放在变量名第一个位子的占位词。
在具体编写 instance method 里,可以不使用 self 这个变量。
如果在 method 里面要改变 instance 的属性,可以用 self.xxxx 来指代这个属性进行修改。
所以self, 就是指由这个 class 造出来的 instance。
类似 JS 中 class 中的 this,指向类的实例
小结:class 表示类,类中的函数 function 就是方法 method,函数的第一个参数是 self,表示类的实例对象。
0328 django 中 skip_common_chunks¶
https://www.5axxw.com/wiki/content/jxx937
一个页面中,render_bundle 如果调用多次,那么会将 common.css 和 common.js 多次插入到页面中
{% render_bundle 'viewDataGrid' 'css' %}
{% render_bundle 'baseStatistic' 'css' %}
{% render_bundle 'viewDataGrid' 'js' %}
{% render_bundle 'baseStatistic' 'js' %}
SKIP_COMMON_CHUNKS是一个标志,用于防止已生成的块再次包含在同一页面中。只有在每个Django模板使用多个入口点(多个render_bundle调用)时,才会发生这种情况。通过启用它,您可以获得与HtmlWebpackPlugin相同的默认行为。当在render_bundle上使用skip_common_chunks时,同样的注意事项也适用,有关更多详细信息,请参阅下面的部分。
{% render_bundle 'viewDataGrid' 'css' %}
{% render_bundle 'baseStatistic' 'css' skip_common_chunks=True %}
{% render_bundle 'viewDataGrid' 'js' %}
{% render_bundle 'baseStatistic' 'js' skip_common_chunks=True %}
0329 django 中 render_bundle¶
render_bundle 是一个 Django 模板标签,用于在模板中引入Webpack打包的静态资源文件。它是通过webpack_loader库提供的功能来实现的。
在给定的引用中,render_bundle被用来引入名为’main’的Webpack打包文件。它接受三个参数:bundle名称、文件后缀和位置。在这个例子中,'main’是bundle名称,'head.js’和’body.js’是文件后缀,'DEFAULT’是位置。
在模板中,render_bundle标签被用在\
和\标签中,分别引入了’main.head.js’和’main.body.js’这两个Webpack打包的文件。下面是一个示例,演示了如何使用render_bundle标签引入Webpack打包的静态资源文件:
{% load render_bundle from webpack_loader %}
<html>
<head>
{% render_bundle 'main' 'head.js' 'DEFAULT' %}
</head>
<body>
...
{% render_bundle 'main' 'body.js' 'DEFAULT' %}
</body>
</html>
0487 Python3 不同版本管理?¶
版本说明¶
不同版本的查看和下载,参考:https://www.python.org/downloads/
python2 版本太老,不建议再使用。
2024年 最新是 python3.12 版本。python 3.12 版本的更新说明:https://docs.python.org/zh-cn/3/whatsnew/3.12.html
目前 3.12 版本
版本管理¶
可以使用 brew, conda 等工具,MAC 系统使用 brew 更方便
# 安装不同的 python 版本
brew install python@3.9
# 查看安装的版本(本地安装了 3.9 和 3.12 版本)
which python3.9
cd /opt/homebrew/bin/
ls | grep python
注意从 python3.8 升级到 python 3.12 一部分语法不能使用,例如 Fabric3 中的 collection 语法。
0490 SQLAlchemy 连接数据库¶
官方介绍:https://docs.sqlalchemy.org/en/14/intro.html
SQLAlchemy 是一个 Python 的 SQL 工具包以及数据库对象映射框架。它包含整套企业级持久化模式,专门为高效和高性能的数据库访问。
核心逻辑:
第一层:ORM 实现了关系型数据库转换成对象结构,python 层面不需要直接操作 SQL 语句,操作 Object 即可完成。
ORM:对象关系映射(英语:Object Relational Mapping,简称ORM,或O/RM,或O/R mapping)
第二层:核心代码实现了 Schema, Types, SQL 语句,连接池,Dialect(方言,是指用于与特定数据库进行交互的配置选项)
第三层:DB API 操作
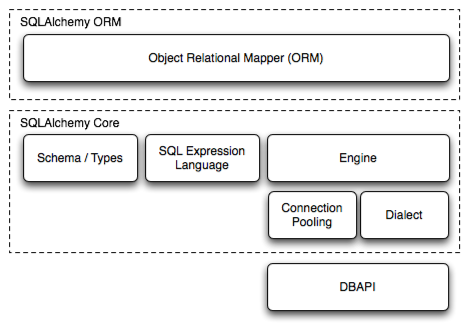
其他博客参考:https://zhuanlan.zhihu.com/p/466056973
示范代码
from sqlalchemy import Column, DateTime, String, Integer, ForeignKey, func
from sqlalchemy.orm import relationship, backref
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Department(Base):
__tablename__ = 'department'
id = Column(Integer, primary_key=True)
name = Column(String)
class Employee(Base):
__tablename__ = 'employee'
id = Column(Integer, primary_key=True)
name = Column(String)
# Use default=func.now() to set the default hiring time
# of an Employee to be the current time when an
# Employee record was created
hired_on = Column(DateTime, default=func.now())
department_id = Column(Integer, ForeignKey('department.id'))
# Use cascade='delete,all' to propagate the deletion of a Department onto its Employees
department = relationship(
Department,
backref=backref('employees',
uselist=True,
cascade='delete,all'))
from sqlalchemy import create_engine
engine = create_engine('sqlite:///orm_in_detail.sqlite')
from sqlalchemy.orm import sessionmaker
session = sessionmaker()
session.configure(bind=engine)
Base.metadata.create_all(engine)
实际使用
# coding: utf-8
import json
import hashlib
from sqlalchemy.orm import mapped_column
from sqlalchemy.sql.sqltypes import Integer, String, DateTime, Text, BigInteger
from sqlalchemy.sql.schema import Index, ForeignKey
class Activity():
__tablename__ = 'Activity'
id = mapped_column(BigInteger, primary_key=True, autoincrement=True)
op_type = mapped_column(String(length=128), nullable=False)
op_user = mapped_column(String(length=255), nullable=False)
obj_type = mapped_column(String(length=128), nullable=False)
timestamp = mapped_column(DateTime, nullable=False, index=True)
repo_id = mapped_column(String(length=36), nullable=False)
commit_id = mapped_column(String(length=40))
path = mapped_column(Text, nullable=False)
detail = mapped_column(Text, nullable=False)
def __init__(self, record):
super().__init__()
self.op_type = record['op_type']
self.obj_type = record['obj_type']
self.repo_id = record['repo_id']
self.timestamp = record['timestamp']
self.op_user = record['op_user']
self.path = record['path']
self.commit_id = record.get('commit_id', None)
detail = {}
detail_keys = ['size', 'old_path', 'days', 'repo_name', 'obj_id', 'old_repo_name']
for k in detail_keys:
if k in record and record.get(k, None) is not None:
detail[k] = record.get(k, None)
self.detail = json.dumps(detail)
def __str__(self):
return 'Activity<id: %s, type: %s, repo_id: %s>' %
TODO:写一个案例到 helloPython 中,实际连接数据库练习
0663 gevent¶
gevent:使用 greenlet 且基于协程的 Python 网络库。
gevent is a coroutine -based Python networking library that uses greenlet to provide a high-level synchronous API on top of the libev or libuv event loop.
greenlet: https://pypi.org/project/greenlet/
gevent: https://pypi.org/project/gevent/
0664 pypandoc¶
https://pypi.org/project/pypandoc/
文件格式转换器,例如 txt 和 markdown 格式的转换
Pypandoc provides a thin wrapper for pandoc, a universal document converter.
There are two basic ways to use pypandoc: with input files or with input strings.
import pypandoc
# With an input file: it will infer the input format from the filename
output = pypandoc.convert_file('somefile.md', 'rst')
# ...but you can overwrite the format via the `format` argument:
output = pypandoc.convert_file('somefile.txt', 'rst', format='md')
# alternatively you could just pass some string. In this case you need to
# define the input format:
output = pypandoc.convert_text('# some title', 'rst', format='md')
# output == 'some title\r\n==========\r\n\r\n'
0665 html2text¶
https://pypi.org/project/html2text/
HTML转换成 MarkDown 格式的工具
html2text is a Python script that converts a page of HTML into clean, easy-to-read plain ASCII text.
Better yet, that ASCII also happens to be valid Markdown (a text-to-HTML format).
html2text库可能无法完美转换所有HTML标签。实际测试,普通 div span 转换正常,复杂的代码块和扩展语法等不支持。
import html2text
print(html2text.html2text("<p><strong>Zed's</strong> dead baby, <em>Zed's</em> dead.</p>"))
# **Zed's** dead baby, _Zed's_ dead.
复杂案例
import html2text
h = html2text.HTML2Text()
# Ignore converting links from HTML
h.ignore_links = True
print h.handle("<p>Hello, <a href='https://www.google.com/earth/'>world</a>!")
# Hello, world!
# Don't Ignore links anymore, I like links
h.ignore_links = False
print(h.handle("<p>Hello, <a href='https://www.google.com/earth/'>world</a>!"))
# Hello, [world](https://www.google.com/earth/)!
详细使用:
https://github.com/Alir3z4/html2text/blob/master/docs/usage.md
0666 pyjwt¶
https://pypi.org/project/PyJWT/
A Python implementation of RFC 7519.
import jwt
encoded = jwt.encode({"some": "payload"}, "secret", algorithm="HS256")
print(encoded)
# eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzb21lIjoicGF5bG9hZCJ9.4twFt5NiznN84AWoo1d7KO1T_yoc0Z6XOpOVswacPZg
jwt.decode(encoded, "secret", algorithms=["HS256"])
# {'some': 'payload'}
0667 python-docx¶
python-docx is a Python library for reading, creating, and updating Microsoft Word 2007+ (.docx) files.
https://pypi.org/project/python-docx/
from docx import Document
document = Document()
document.add_paragraph("It was a dark and stormy night.")
# docx.text.paragraph.Paragraph object at 0x10f19e760>
document.save("dark-and-stormy.docx")
document = Document("dark-and-stormy.docx")
document.paragraphs[0].text
# 'It was a dark and stormy night.'
0668 pymysql¶
https://pypi.org/project/PyMySQL/
新建数据库表
CREATE TABLE `users` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`email` varchar(255) COLLATE utf8_bin NOT NULL,
`password` varchar(255) COLLATE utf8_bin NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
import pymysql.cursors
connection = pymysql.connect(host='localhost',
user='user',
password='passwd',
database='db',
cursorclass=pymysql.cursors.DictCursor)
with connection:
with connection.cursor() as cursor:
# Create a new record
sql = "INSERT INTO `users` (`email`, `password`) VALUES (%s, %s)"
cursor.execute(sql, ('webmaster@python.org', 'very-secret'))
# connection is not auto commit by default. So you must commit to save your change
connection.commit()
with connection.cursor() as cursor:
# Read a single record
sql = "SELECT `id`, `password` FROM `users` WHERE `email`=%s"
cursor.execute(sql, ('webmaster@python.org',))
result = cursor.fetchone()
print(result)
0669 time sleep()¶
Python
time sleep() 函数推迟调用线程的运行,可通过参数 secs 指秒,表示进程挂起的时间。
#!/usr/bin/python
import time
time.sleep(5)
注意是秒,不是毫秒
0683 python 读取本地文件¶
Python 读取本地文件常见的方法:
1、内置的open函数
这种方法使用了上下文管理器(context manager)来自动关闭文件,读取文件内容存储在变量content中。
with open('文件路径', 'r') as file:
content = file.read()
2、使用readlines方法逐行读取文件内容,并存储在列表中
这种方法逐行读取文件内容存储在列表lines中,每一行作为一个元素
with open('文件路径', 'r') as file:
lines = file.readlines()
3、使用readline方法逐行读取文件内容,并逐行处理
with open('文件路径', 'r') as file:
line = file.readline()
while line:
# 处理当前行
...
# 读取下一行
line = file.readline()
0670 Beautiful Soup¶
官方文档链接
https://beautifulsoup.readthedocs.io/zh-cn/v4.4.0/#
个人总结:
https://michael18811380328.github.io/python/third-part-lib/001-Beautiful-Soup/
实际使用:
https://github.com/Michael18811380328/HelloPython/tree/master/src/spider
0684 python 提取高频词 jieba¶
要在Python中提取高频词,可以使用jieba库进行中文分词,并使用collections库中的Counter类来统计词频。
自然语言处理
import jieba
from collections import Counter
# 输入文本
text = "这里是一段中文文本,用于演示如何提取高频词。"
# 使用jieba进行分词
words = jieba.cut(text)
# 转换为列表
words = list(words)
# 停用词列表
stopwords = ['用于', '的', '是', '一段', '演示', '如何']
# 移除停用词
words = [word for word in words if word not in stopwords]
# 统计词频
word_counts = Counter(words)
# 设定高频词阈值,例如出现超过2次
threshold = 2
# 提取高频词
high_frequency_words = [word for word, count in word_counts.items() if count > threshold]
print(high_frequency_words)
0685 python 提取高频词 nltk¶
使用NLTK库来提取文本中的高频词(即词频统计中频率最高的词)。
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# 加载停用词(或者本地新建一个停用词库)
nltk.download('stopwords')
stop_words = set(stopwords.words('english'))
# 示例文本
text = "Python is a high-level, general-purpose, dynamic programming language. Python's design philosophy emphasizes code readability with its notable use of significant whitespace. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects."
# 进行词标记
tokens = word_tokenize(text)
# 移除停用词
tokens = [token for token in tokens if token not in stop_words]
# 计算词频
freq_dist = nltk.FreqDist(tokens)
# 提取高频词
high_freq_words = [word for word in freq_dist.keys() if freq_dist[word] > 1]
print(high_freq_words)
0686 collections¶
https://blog.csdn.net/peng78585/article/details/125387640
https://docs.python.org/zh-cn/3/library/collections.html#module-collections
主要用于统计和计数
import jieba
from collections import Counter
text = "这里是一段中文文本,用于演示如何提取高频词。这里是一段中文文本,用于演示如何提取高频词。这里是一段中文文本,用于演示如何提取高频词。这里是一段中文文本,用于演示如何提取高频词。这里是一段中文文本,用于演示如何提取高频词。这里是一段中文文本,用于演示如何提取高频词。"
# 使用 jieba 进行分词
words = jieba.cut(text)
# 转换为列表
words = list(words)
# 停用词列表
stopwords = ['用于', '的', '是', '一段', '演示', '如何']
# 移除停用词
words = [word for word in words if word not in stopwords]
# 统计词频
word_counts = Counter(words)
# 设定高频词阈值,例如出现超过2次
threshold = 2
# 提取高频词
high_frequency_words = [word for word, count in word_counts.items() if count > threshold]
print(high_frequency_words)
0696 raise 使用¶
raise 处理错误信息,类似 JS 中的 throw,可以主动抛出一个错误(可以定义错误的类型和信息)
https://www.runoob.com/python/python-exceptions.html
https://blog.csdn.net/weixin_45353453/article/details/120412064
def divideNum(num):
try:
100 / num
except Exception as res:
print("finish")
print(res)
raise ZeroDivisionError
print("----can not print this code-----")
else:
print("no error")
divideNum(100)