AI笔记¶
统计信息:字数 9057 阅读19分钟
原始笔记链接:https://cloud.seatable.cn/dtable/external-links/59b453a8639945478de2/
0690 日常使用了哪些AI¶
CHATGPT 等大模型是核心,其他很多套壳的工具和应用
国外的 Codeium Monica CodeGeex 等插件,辅助变成,查询资料
中文的文心一言,豆包等模型
0691 项目中使用了哪些 AI¶
项目中 AI 主要是后端实现具体逻辑,或者是调用外部大模型,前端目前在 AI 技术上进行集成
1、AI 助手,赋能传统软件:原来的逻辑是用户需要直接点击按钮,或者进行复杂操作,统计数据。现在我们写了一些 AI 助手,根据用户的自然语言描述,使用开源大模型,然后转换成对应的代码,执行对应的 API 或者功能(统计某人本周的任务,统计表格整体的信息,以统计图形式展现出来),实现了传统软件赋能。
2、AI 搜索,增强搜索范围:这是内部实现的一个 Go 服务,前端调用实现 AI 搜索。关键是文本的分词和分析等,然后计算不同文档的匹配度。zincsearch 基础上改动的。替换了原来的 es 搜索,需要的资源更少 https://github.com/zincsearch/zincsearch
3、AI 识别,智能管理图片:识别发票图片,然后进行填写,避免用户手动录入数据。我们内部的技术实现调用了某某的图片识别接口(还有其他身份证,驾照,发票识别等等)市场上有一些开源的工具,例如前端的 tesseract 可以进行识别,但是准确率不是很高,所以我们使用了其他的 AI 接口。
0736 Llm 基本概念¶
本文介绍了 LLM 的基本概念,通俗易懂,英文原文链接:https://towardsdatascience.com/understanding-llms-from-scratch-using-middle-school-math-e602d27ec876
如何通过简单的加法和乘法来分类对象(如叶子或花朵)并解释了下述的概念——
-
输入数据:叶子和花朵的RGB颜色和体积。
-
神经元、权重和层:节点对应神经元、连接线上的数值即为权重,图中可以清晰看到网络的层结构(输入层、中间层、输出层)。
-
输出解释:使用两个输出神经元分别表示“叶子”和“花朵”,通过比较输出值的大小来进行分类,分类结果。

模型的训练方式:
-
训练目标:通过调整权重,使模型能够正确地对输入进行分类。
-
损失函数:说明如何计算损失(loss),以及损失函数在模型训练中的作用。
-
梯度下降:介绍梯度下降算法如何用于优化模型参数,以最小化损失。
-
迭代过程:描述训练过程中的迭代步骤,包括多次遍历训练数据(epochs),以及如何避免过拟合。
生成语言的原理:
-
从字符到句子:讨论如何将神经网络应用于语言生成,通过预测下一个字符来逐步构建句子。
-
输入和输出的表示:提出将字符映射为数字的方法,以及如何解释模型的输出为下一个字符。
-
固定的上下文长度:解释在生成过程中,输入的长度是固定的,这被称为“上下文长度”(context length)。模型只能利用有限的上下文信息进行预测。

大型语言模型的有效性原因:
-
模型的局限性:指出简单的字符预测模型的局限性,如无法捕捉长距离依赖和复杂的语言结构。
-
改进方法:引入更复杂的技术,如嵌入、子词分词器和自注意力机制,以提升模型的性能。
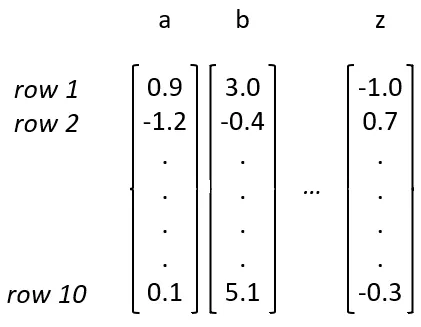
嵌入(Embeddings):
-
概念:说明嵌入是如何将离散的字符或词映射为连续的向量表示,以捕捉它们之间的语义关系。
-
训练嵌入:在训练过程中,同时优化嵌入向量,使模型能够更好地理解输入数据。
-
向量表示的优势:使用多维向量表示字符或词,可以更丰富地捕捉语言的特征。
子词分词器(Subword Tokenizers):
-
动机:直接使用词作为基本单元会导致词汇量过大,模型难以处理。
-
方法:将词分解为更小的子词或字符(如使用SentencePiece分词器),这样可以降低词汇量,同时捕捉词形变化和词缀信息。
-
示例:展示如何将“cats”分解为“cat”和“s”,从而利用“cat”的已有信息,提升模型的泛化能力。
自注意力机制(Self-Attention):
-
问题背景:传统的神经网络难以捕捉序列中远距离词之间的依赖关系。
-
解决方案:自注意力机制允许模型根据输入序列中不同位置的词,动态地调整它们的重要性。
-
具体实现:
-
查询(Query)、键(Key)和值(Value):引入这三个概念,说明如何计算注意力权重。
-
计算过程:通过点积计算注意力得分,使用Softmax函数归一化权重,然后加权求和得到输出。
-
优势:自注意力机制能够高效地捕捉序列中不同位置的依赖关系,无论它们之间的距离多远。
Softmax函数:
-
作用:将模型的原始输出转换为概率分布,使得输出的各个元素之和为1。
-
必要性:在多分类问题中,需要将输出映射为概率,以便进行合理的预测和计算损失。

残差连接(Residual Connections):
-
问题背景:随着网络层数的增加,训练深层神经网络会遇到梯度消失或爆炸的问题。
-
解决方案:残差连接通过在层与层之间添加直接的捷径连接,缓解了梯度消失问题,使得信息能够更直接地传递。
-
效果:这种结构提高了模型的训练稳定性和性能。

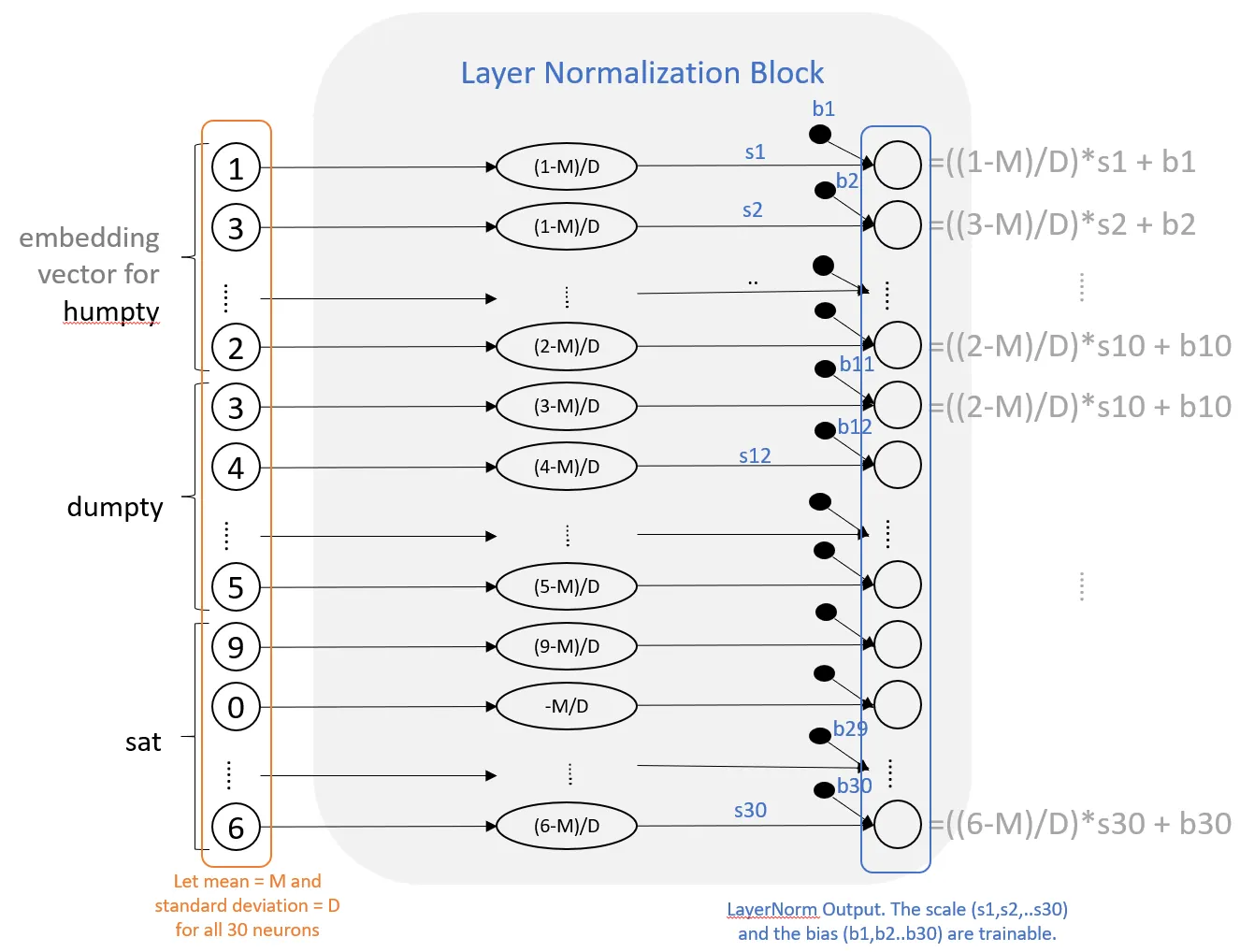
层归一化(Layer Normalization):
-
概念:在每个层对输入进行归一化处理,减去均值,除以标准差,然后应用可训练的缩放和平移参数。
-
作用:加速模型训练,稳定梯度,提高模型的泛化能力。
Dropout:
-
概念:在训练过程中,随机丢弃一部分神经元的连接,以防止模型过拟合。
-
原理:通过让模型在训练时学习多个子模型的集成,从而提高模型的鲁棒性。
多头注意力(Multi-Head Attention):
-
概念:在自注意力机制的基础上,引入多个“头”,让模型能够从不同的子空间中学习表示。
-
实现:对输入进行线性变换,生成多个查询、键和值,然后并行地计算注意力,最后将结果拼接起来。
-
优势:增强模型的表达能力,使其能够捕捉更丰富的特征。
位置嵌入(Positional Embedding):
-
问题背景:自注意力机制本身不考虑序列中元素的位置信息。
-
解决方案:通过为每个位置添加一个位置嵌入向量,将位置信息显式地编码到输入中。
-
方法:使用可训练的嵌入向量,或者采用固定的正弦和余弦函数进行位置编码。
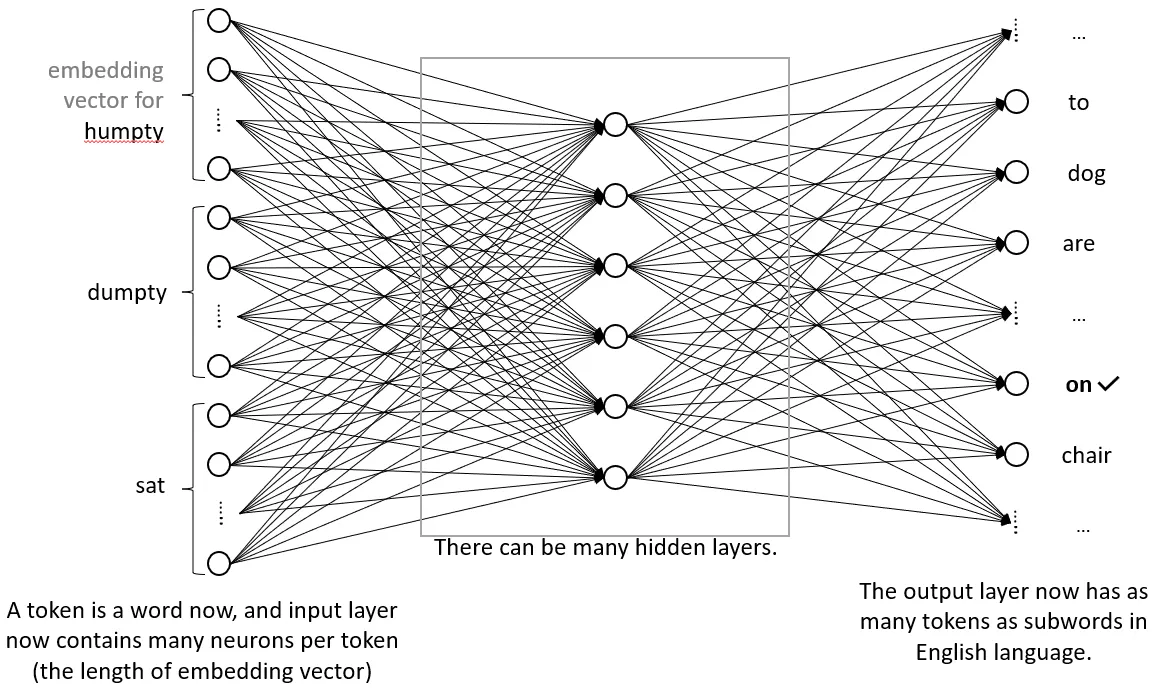
GPT架构:
-
整体结构:将前面介绍的所有组件组合起来,构建了GPT模型的完整架构。
-
流程:
-
输入层:将输入的文本通过词嵌入和位置嵌入进行编码。
-
Transformer块:包含多头自注意力、残差连接、层归一化和前馈神经网络等组件。
-
输出层:通过Softmax函数,预测下一个词或字符的概率分布。
-
特点:GPT模型主要用于文本生成,能够根据给定的上下文,生成连贯的文本。
Transformer架构:
-
背景:Transformer模型最初是为了解决机器翻译等序列到序列的任务。
-
结构:由编码器(Encoder)和解码器(Decoder)组成。
-
编码器:对输入序列进行编码,捕捉其语义表示。
-
解码器:根据编码器的输出和已生成的序列,生成目标序列。
-
创新点:完全基于注意力机制,摒弃了传统的循环神经网络(RNN)结构,提高了并行计算效率。
