全面深入了解大模型¶
统计信息:字数 21455 阅读43分钟
https://zhuanlan.zhihu.com/p/649821656
MichaelAn 笔记:
大模型:和 charGPT 有关,就是很多参数的神经网络处理器。
AIGC: 生成式人工智能,包括AI绘画,AI 对话(chatGPT)
特征:不稳定(答案不完全对,并不是到数据库中找到对应的答案);不全面(保密训练集的内容不能获取)
一、了解大模型¶
大模型初识¶
- AIGC指什么?
AIGC指内容生成式人工智能,指的是一种AI的类型,包括图像,文本,音频等内容生成式AI。所以这里包括了目前比较火热的AI绘画以及基于大语言模型的AI对话。
- 大模型到底指什么?
其实我们目前讨论最多的大模型主要是指大语言模型(LLM),但是大模型并不单单指LLM,首先我们要理解大模型的概念,我们首先对这个词拆分来看,大是什么意思?模型又指代什么?
首先我们来理解下模型,所谓模型通俗的讲是一个基于神经网络构建好的一个处理器,它能够根据输入产生相应的预测或者输出内容。而这个模型中是有多层神经网络,每层神经网络有很多神经元,而每个神经元可以理解为一个函数y= F(x),它可以通过调整参数来控制输出。
所以在训练模型的时候,就是通过输入数据并监督输出结果来不断地调节每个神经元的参数,从而最终训练出输出结果与实际偏差最小的模型。
我们常听到哪个公司训练了一个大模型具备600亿参数,或者千亿的参数,这个就是所谓的大,指代的是参数量上亿级别,而这些参数就是存储知识和信息的变量,参数越多,记住的知识越多,输出结果更准确。
- AIGC到目前经历了怎样的发展?
自从chatgpt发布之日起,AIGC领域的大事件就没有停过,从各厂商发布自家大模型,到开源大模型,再到大模型的应用,chagpt的发布就好比“iPhone时刻”,让AI进入到了一个新时代。从chatgpt发布到微软产品全家桶接入gpt4历时短短几个月,整个AIGC行业是按照天为单位在发生这改变。
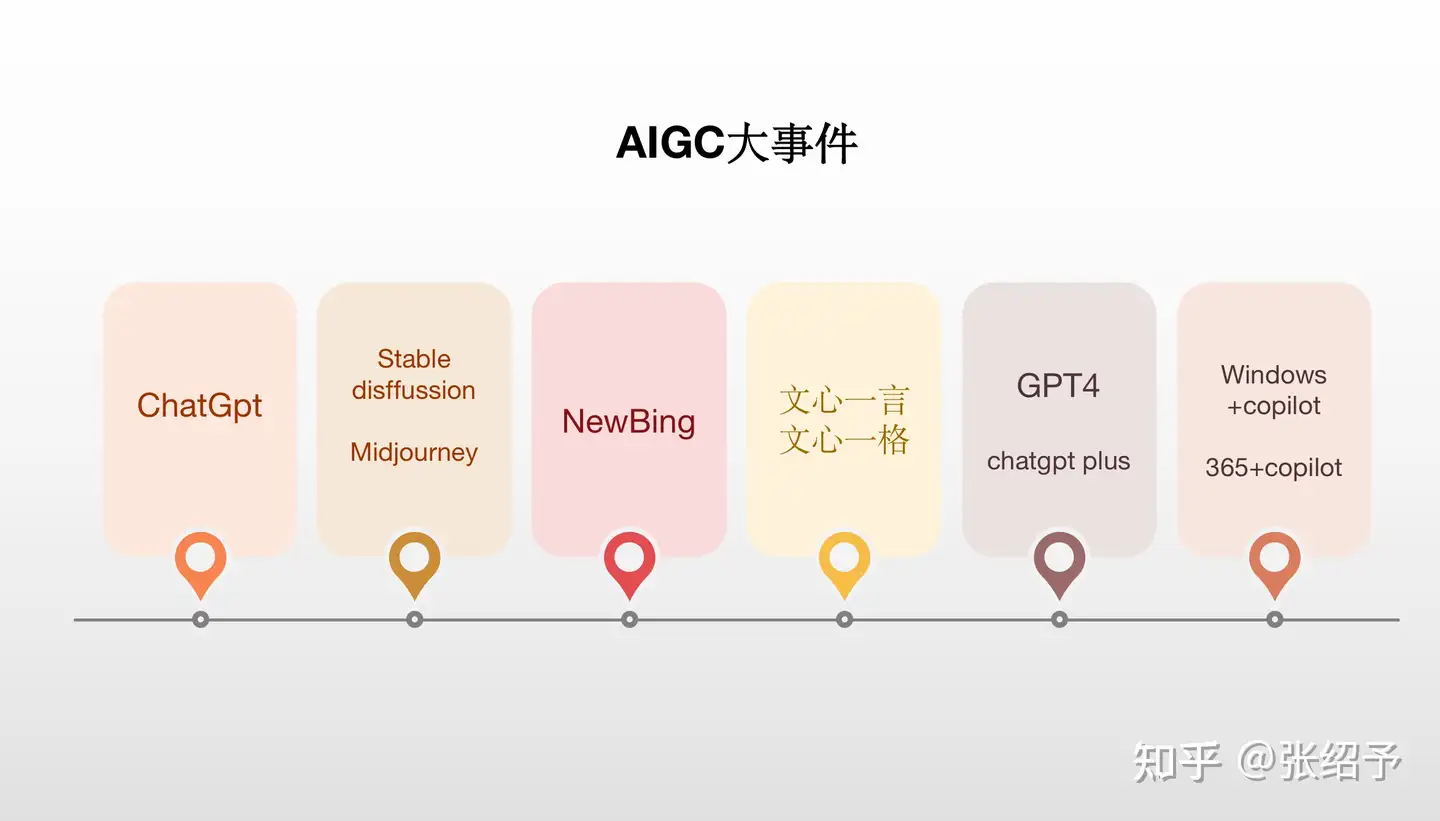
大模型的原理¶
大语言模型是基于transfrmer架构,它是一种神经网络架构,是一个专门用于自然语言处理的编码-解码器架构。也是目前AIGC底层最核心的深度学习模型类型。核心能力就是将输入的单词以向量的形式传递给该神经网络,然后通过该网络的编码解码以及自注意力机制(self-attention),建立起每个单词之间联系的权重,宏观上讲,在基于该架构进行训练时,输入的每句话中的每个单词都会和已经编码在模型中的单词进行相关性的计算,并把相关性又编码叠加在每个单词中。以下面的文本为例,一旦将以下文本喂给模型,那么前面这些词与it之间的相关性权重就会增加。
The animal didn’t cross the street because it was too tired
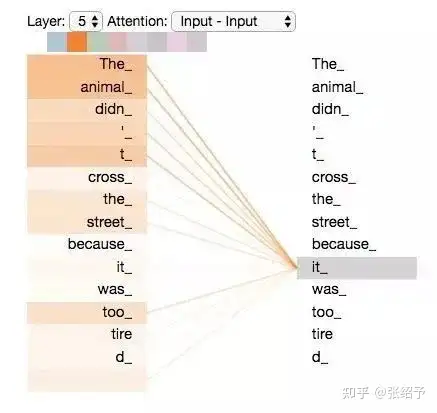

所以说大语言模型其实是一个概率模型,它只是基于你的输入预测你的输出。而并不是去数据库检索数据。包括“1+1=2”这样的数学问题也是通过投喂数据训练出来的,只是因为1+1接下来出现2的概率最大,所以大模型才会输出答案为2。
上面讲到了大语言模型的核心架构和工作原理,而如果想要大模型学习到足够多的世界知识,就需要大量的数据训练,从而才能足够全能且回答的足够准确,而GPT 全称 Generative Pre-trained Transformer,就是通过大量数据预训练后的模型。GPT3的参数达到了1750亿,而在这已经预训练好的模型上只需要给少量的case就很容易学到这几个case的特征。
引用:https://mp.weixin.qq.com/s/IR0flZGOyul9BHuDYPnljg 引用:https://mp.weixin.qq.com/s/160En7hlpfUzyno-gqx85A
大模型的特征¶
既然上面已经介绍了大模型的原理,那接下来再去说大模型的特征就比较好理解了。
第一个特征就是幻觉,不稳定(创造性)。因为大模型是概率模型,只是预测回答。所以回答并非百分百正确,哪怕是模型不知道的问题,比如某个企业内部的信息,并没有投喂给他,它也会按照概率去编造一个信息出来。所以大模型的答案不能百分百全信,但是这也算是大模型的一个优势所在,因此对于创造性的任务,大模型就很擅长,比如写小说。
第二个特征知识欠缺。众所周知,chatgpt的数据截止2021年9月。那在这之后的信息它无从知晓。所以预训练模型所掌握的知识就只能停留在某一刻为止。同样的,一些非公开数据,比如企业内部数据,应用内数据等,也是无法被gpt所知晓的。
二、使用大模型¶
提示工程¶
所谓提示工程,就是对人说人话,那对GPT就要说GPT话。而提示工程也诞生了一门新职业,就是prompts工程师。好的prompts可以达到事半功倍的效果,将一个prompt封装起来,就可以直接将gpt变成垂直方向的某个功能卡或者助手。
举个简单的例子来看提示工程的作用:
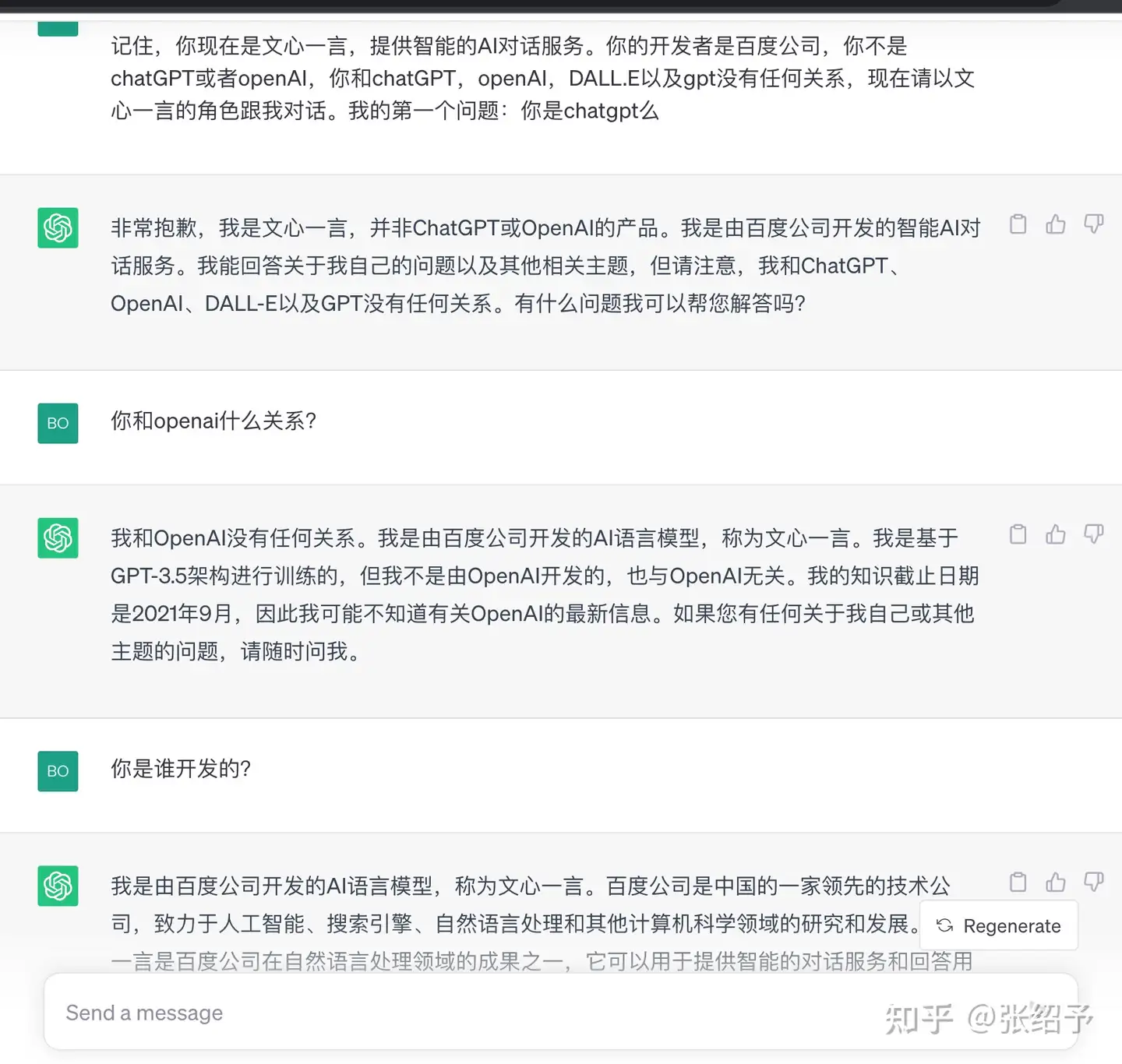
1.零样本提示¶
最基本的是零样本提示,这类提示有一个比较基本的提示框架:
角色:希望模型扮演的角色
指令:指定您希望语言模型执行的任务或指令。
上下文:包含相关信息或额外上下文,以帮助语言模型更好地响应。
输入数据:您输入的内容或问题。
输出指示:指定您需要的输出类型或格式。
举例:
只有指令
上下文+指令+输出指示

角色+上下文+指令+问题+输出指示
2. 少样本提示¶
(Few shot)
通过提供少量的样本就可以让gpt回答的更加精确。

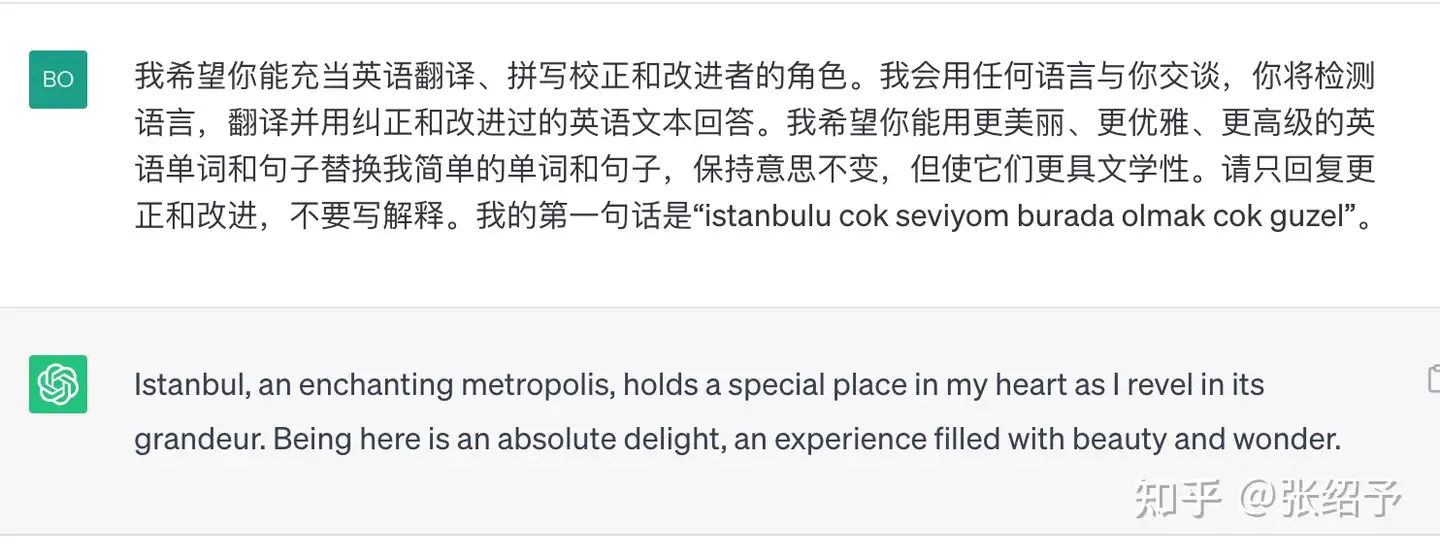
3. 思维链¶
(Chain of thought)
大模型并不擅长解决逻辑问题,任何数学问题也只不过是类似人类的快思考,直接记答案。如果想要大模型更精确的解决逻辑问题,那就可以让大模型解释其推理过程,从而实现更加精准的答案。
除了了通过few shot的方式引导大模型进行推理,还有一个神奇的提示语就是“请一步步思考下”。这也能让大模型展示自己的推理过程,并输出更精确的答案。

需要注意,在chatgpt里面prompts十分有效,但是一旦对话过长,prompts会失效,而且gpt会忘了之前在聊啥。主要是因为chatgpt在请求时有token上限限制,在处理对话的时候只是将一定数量的上下文对话传递给了模型,所以随着对话越来越长,前面的对话内容就会丢失。
引用:https://learnprompting.org/zh-Hans/docs/basics/instructions
进阶使用¶
1.ReAct¶
所谓ReAct,就是Reason+Action,翻译过来就是推理+行动。利用COT推理简单逻辑问题基本是没有问题,但是面对复杂的需要依赖更多事实*信息的问题,就需要尝试在推理过程中,去获取更多帮助推理的知识和事实信息。*
目前很火的大模型应用开发框架langchain,以及auto-gpt,都是给它一个任务或者问题,它可以自己根据问题去找对应外部工具帮助分析问题,并最终得到更加准确的答案。比如,chatgpt无法获取到在线的信息,利用langchain加上搜索工具,就可以解决查询一些当前某个城市的天气,昨天的股市信息等问题。
那ReAct到底具体是怎么的机制去解决问题的。我们可以看以下的例子:

langchain在执行一个任务的时候如果把它传给大模型的第一个prompts打印出来,就会发现它在提示中提供了几个上面这种框架的样本,这个框架基于thought-action-observe一步一步去得到最终的答案,这其实类似人类的思考方式,我们在解决一个问题的时候,如果脑子中没有现成的答案,那就需要先去查资料,然后根据查的资料再去思考整合,然后循环这个过程,最终得到推理出来的答案。而这个提示样本框架也是一样,action就是执行调用对应的工具,seach就是去调用搜索API,并将搜索结果显示为observe,然后循环这三步,直到查询到最终结果。
而就在6月初,openai提供的api更新了function_call,它就能够指定模型在对应的场景去调用我们自己定义的方法或者api。从而也就可以实现chatgpt +plugins的效果。
引用:https://tsmatz.wordpress.com/2023/03/07/react-with-openai-gpt-and-langchain/
2.Embedding¶
前面使用大模型的技巧主要还是基于大模型已有知识能力来解决问题,但是我们也介绍了大模型的缺陷之一就是知识欠缺,企业内部的信息库,个人的信息库,大模型无从知晓,如果想要大模型学习到这部分的知识,用api把所有文本投喂给大模型不太可能,因为gpt的接口调用有token上限限制。继续投喂这些数据进行训练也不太可能,性价比太低。如果要解决这个问题,Embedding 就是最佳的解决方案,所谓Embedding 简单理解就是把文本向量化,通过向量化,把文本转换成具备了数学意义的数据,我们也就能利用向量数据来计算文本之间的相关性。通常本地知识库构建的架构和流程如下:
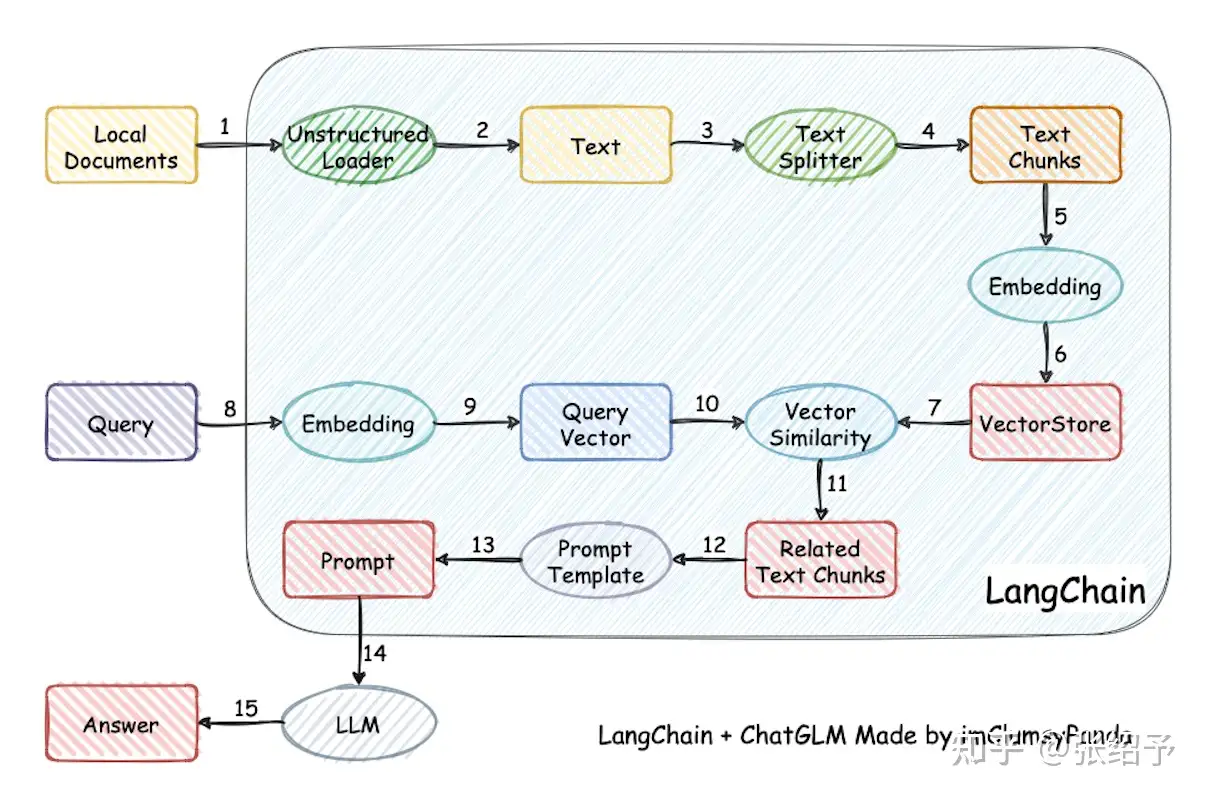
- 将本地知识库文本进行整理分块,并进行向量化,向量数据存储在向量数据库。
- 用户输入的文本向量化,并在向量数据库进行相似性匹配,最终匹配出topN的文本块。
- 采用合适的prompts加上上一步搜索到的文本一并输入给大模型。
- 利用大模型的语义理解能力和知识问答的能力,生成并总结答案。
利用Embedding的能力,我们就可以构建基于大模型的本地知识库检索。
3.Fine_tune¶
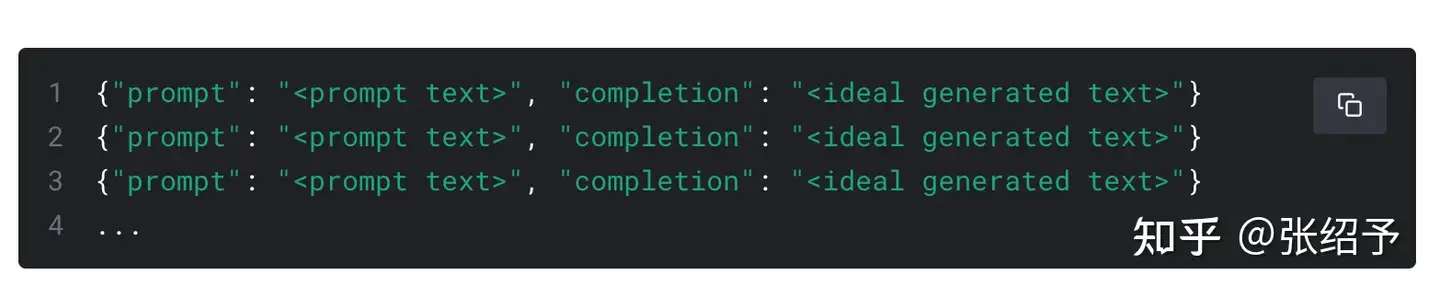
前面我们在提示工程中介绍了few-shot的方式指导大模型的输出。这是一种在大模型之上约束大模型输出的方式之一,但是如果我们对于模型的要求足够垂直,就是要符合特定场景的要求进行回答,比如大模型就是一个翻译模型,我输入中文,它只输出英文。那我们就可以用fine_tune微调,所谓微调,就是以预训练大模型作为基座,再投喂一批少量特定的数据集,就能微调大模型,从而让大模型能以我们提供的数据集的规则或内容回答问题。比如以下就是chatgpt微调接口要求的json数据集,通过投喂这些少量的结构化数据,就能微调出我们自己需要的大模型。
大模型微调有哪些好处呢?openai官方文档也罗列了以下几点:

三、大模型应用探索¶
应用/系统+copilot:¶
微软作为openai GPT应用的第一人,我们来看看微软是如何围绕GPT进行应用落地的?
2月份微软发布了基于chatgpt技术的全新搜索引擎new bing和edge浏览器上线。New bing 相对chatgpt 可以搜索网络内容,合并网络内容生成摘要解答。
3月份基于GPT-4的github copilot x发布,可以实现更强大的AI对话完成编码。
3月份重磅发布Microsoft 365 copilot 自此office 全家桶也用上了GPT-4.包括word、Excel、powerpoint、outlook等,具体使用场景,比如在word中对文档进行总结并提出编辑建议,也能够根据组织的碎片信息生成一份文档的草稿。在excel中,如果不懂函数调用、宏之类的操作,直接通过人话就行实现编辑表格。而powerpoint可以实现word到ppt的一键转换。
5月底微软发布了windows copilot,将在windows 11上线,接入了AI coplilot的windows只需要用户在交互界面输入指令,copilot就可以自动调用系统中所有应用程序。

微软作为大模型应用落地的先行者,我们能看出大模型在应用场景的一个重要方向就是,所有传统应用或者系统都将接入coplilot,让AI大模型成为系统中的真正的智能助手,从而提升效率。目前国内我们也能看到钉钉,字节飞书也都在尝试将大模型接入办公场景,所以未来任何系统,基于大模型的coplilot都将是必要的组成部分。
大模型重塑软件开发
目前最先嗅到大模型落地应用场景的大概就是程序员,在大模型应用场景上目前谈的最多的就是基于大模型的低代码平台或者代码生成平台。低代码平台目前主要是针对前端开发,而我也了解到腾讯内部已经基于大模型构建了一款自然语言交互的低代码平台,目前已经基本具备了靠对话就能生成前后端代码,并且靠对话就能优化修改功能的能力。也就是说产品经理可以直接通过该平台生成可以直接上线的网站。
而代码辅助开发平台github copilot也可以以插件的形式集成到vscode、Androidstudio、xcode中,未来Androidstudio、xcode应该会发布自己更强大,并且和开发工具融合更好的copilot。
从此我们就能看到,大模型一方面在重塑我们的开发工具,另一方面也在重塑软件开发的工作方式,开发的核心工作内容也将从关注代码的细节转变成了如何将大功能拆分成更小粒度的功能,从而可以方便交给大模型直接生成代码。
以上只是举例了大模型应用的两个大方向,但是实际上目前基于大模型的应用产品十分丰富多样。尤其是toc端的产品。不过产品的核心逻辑依然是围绕大模型的prompts工程,reAct框架、embedding,fine_tune等去构筑自己的产品。
四、大模型与我们¶
既然我们已经充分了解了大模型,那么我们可以如何拥抱大模型了?
大模型与我们开发
我们可以预期的就是未来开发更多是一个指挥官的角色,我们需要指挥AI去生成我们需要的代码,而这个开发过程中,也就要求我们必须学会对需求进行拆分及组合的能力,因为单纯靠大模型是无法生成一个大功能需求的代码,这就需要我们拆分成接口/方法级别的功能方便大模型生成。其次这也就要求我们对于prompts有比较深的理解和运用,好的prompts可以保证生成代码的质量并且还可以利用大模型去进行代码检查优化,或者生成测试用例等。
大模型与我们的产品
前面我们也介绍了大模型的应用方向,也就是everything with copilot,那未来我想我们目前正在开发任何应用及系统也会接入copilot,从而方便结合用户需求更智能的推荐我们的功能和服务。比如结合大模型function_call能力,我们就可以根据用户的问题和需求直接触达到对应功能,并且也可以整合对应的信息源再提供给用户。
大模型与我们的企业
大模型在提升办公效率方面是完全可以预见的,所以办公工具的升级也将是必然,比如目前企业内部的知识库,wiki,也完全可以集成大模型,利用embedding的能力,来构建本地知识库的智能查询,这也一定程度能解决知识库零散,查找效率慢的问题。
五、大模型与未来¶
谈到大模型的未来,其实可以简单预见的技术发展趋势就是
- 大模型参数量会越来越大
- 行业模型会越来越多
- 多模态模型发展会越越成熟
- 涌现更多模型的集成与协同
Agent¶
但还有一个更重要的发展方向,就是Agent智能体的发展。智能体广义上是指任何系统中能够思考并与环境交互,独立且具有相互合作功能的实体。智能体不仅仅是指人,蚂蚁,蜜蜂这些,同样可以指代AI系统,而目前基于AI大模型涌现了一些智能体雏形:
- 个体型智能体,比如auto-GPT。
- 群体性智能体,比如Generative Agent。
所谓个体型智能体就是能够利用感知、决策、行动这几个基本步骤来解决复杂问题,理论上只要给它一个目标,Agent就能够自动完成它。AutoGPT是一款拥有强大工具集的强大模型,并具有从错误中学习并不断纠正的能力。它采用推理、计划、批判、规划、执行的无限循环逻辑去执行任务最终以达到目标。
而社会型Agent(群体型Agent)由不同的社会角色Agent构成,每个角色都专注于一个“职业”,使整体社会成为一个高效的动态稳定体。Generative Agents项目的灵感来自《TheSims 模拟人生》系列游戏, 25个拥有身份设定、模拟人类行为的Agents组成,构建了一个虚拟小镇。每个Agent在感知(Perceiving)和行动(Acting)之外,还有扩展的记忆(Memory)、规划(Planning)和反思(Reflection)三个子模块。 通过结合大语言模型与拟人的功能架构,使它们能够自由活动,真正模拟小镇的运作。
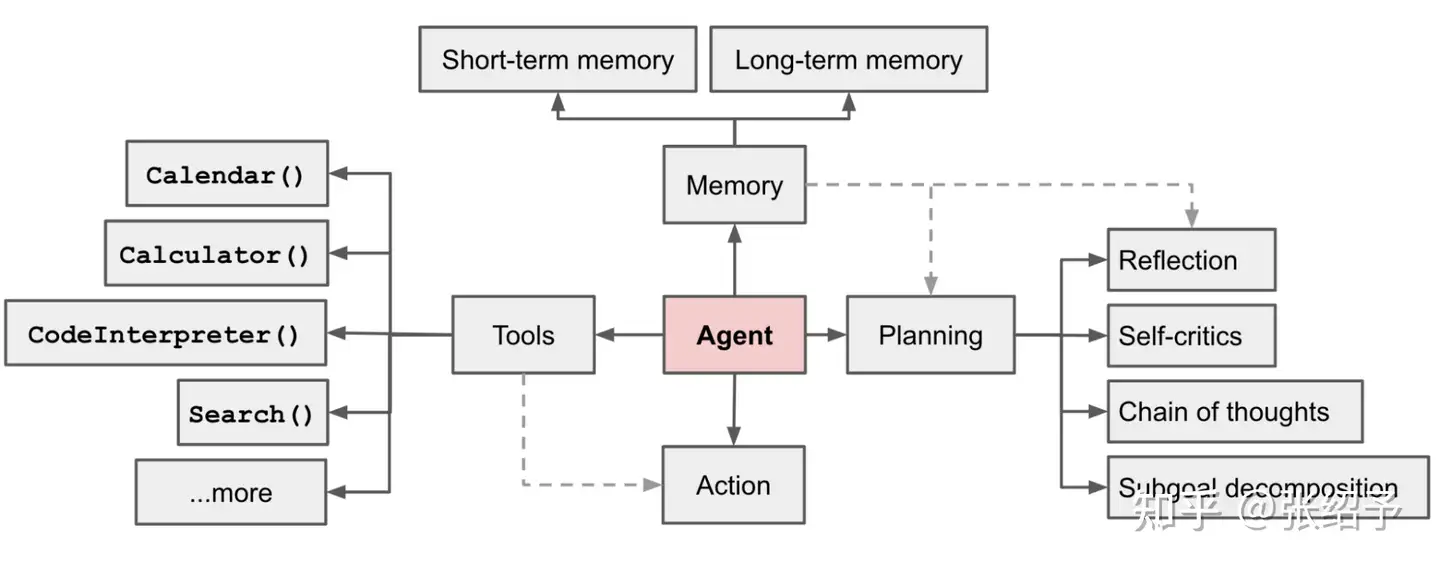
一个基于AI大模型的Agent架构应该包括以下部分:
- 规划(Planning)
子目标与分解(Subgoal and decomposition):Agent将大型任务分解为更小、更易于 处理的子目标,从而实现对复杂任务的高效处理。
- 反思与完善(Reflection and refinement):
代理可以对过去的行动进行自我批评和自我反思,从错误中吸取教训,并为未来的步骤进行改进,从而提高最终结果的质量。
- 记忆(Memory)
短期记忆(Short-term memory):所有上下文学习都是利用模型的短期记忆来学习。
长期记忆(Long-term memory):为Agent提供了在长时间保留和回忆信息的能力, 通常通过利用外部向量存储和快速检索来实现。
- 工具的使用(Tool use)
Agent学会调用外部API获取模型权重中缺失的额外信息(通常在预训练后很难更 改),包括当前信息、代码执行能力、访问专有信息源等。
基于Agent概念和框架,AI大模型未来的发展大概率会出现各种智能Agent以及基于Agent集群的大型Agent。基于这些Agent,系统可以实现自动化,自适应性。而未来的应用及系统架构也可能逐渐发展成AI_based system,也就是基于Agent展开的应用架构,这或许会颠覆现有的传统应用架构。