常见的前端架构风格和案例¶
统计信息:字数 29919 阅读60分钟
原文链接:
https://juejin.cn/post/6844903943068205064
所谓软件架构风格,是指描述某个特定应用领域中系统组织方式的惯用模式。架构风格定义一个词汇表和一组约束,词汇表中包含一些组件及连接器,约束则指出系统如何将构建和连接器组合起来。软件架构风格反映了领域中众多系统所共有的结构和语义特性,并指导如何将系统中的各个模块和子系统有机的结合为一个完整的系统
没多少人能记住上面的定义,需要注意的是本文不是专业讨论系统架构的文章,笔者也还没到那个水平. 所以暂时没必要纠结于什么是架构模式、什么是架构风格。在这里**尚且把它们都当成一个系统架构上的套路, 所谓的套路就是一些通用的、可复用的,用于应对某类问题的方式方法. 可以理解为类似“设计模式”的东西,只是解决问题的层次不一样**。
透过现象看本质,本文将带你领略前端领域一些流行技术栈背后的架构思想。直接进入正题吧
文章大纲
分层风格¶
没有什么问题是分层解决不了,如果解决不了, 就再加一层 —— 鲁迅
不不,原话是:
Any problem in computer science can be solved by anther layer of indirection.
分层架构是最常见的软件架构,你要不知道用什么架构,或者不知道怎么解决问题,那就尝试加多一层。
一个分层系统是按照层次来组织的,每一层为在其之上的层提供服务,并且使用在其之下的层所提供的服务. 分层通常可以解决什么问题?
- 是隔离业务复杂度与技术复杂度的利器. 典型的例子是网络协议, 越高层越面向人类,越底层越面向机器。一层一层往上,很多技术的细节都被隐藏了,比如我们使用
HTTP时,不需要考虑TCP层的握手和包传输细节,TCP层不需要关心IP层的寻址和路由。
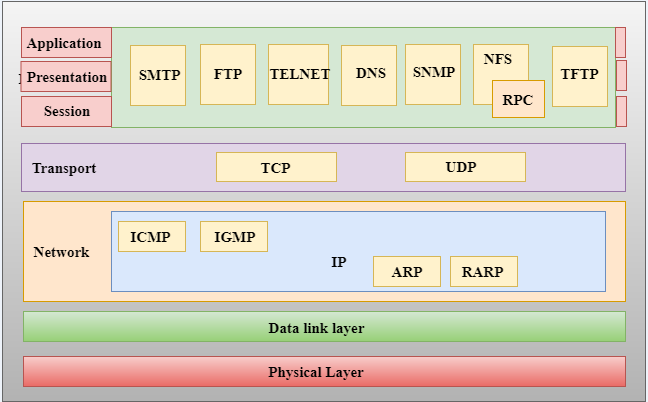
- 分离关注点和复用。减少跨越多层的耦合, 当一层变动时不会影响到其他层。例如我们前端项目建议拆分逻辑层和视图层,一方面可以降低逻辑和视图之间的耦合,当视图层元素变动时可以尽量减少对逻辑层的影响;另外一个好处是, 当逻辑抽取出去后,可以被不同平台的视图复用。
关注点分离之后,软件的结构会变得容易理解和开发, 每一层可以被复用, 容易被测试, 其他层的接口通过模拟解决. 但是分层架构,也不是全是优点,分层的抽象可能会丢失部分效率和灵活性, 比如编程语言就有'层次'(此例可能不太严谨),语言抽象的层次越高,一般运行效率可能会有所衰减:
分层架构在软件领域的案例实在太多太多了,咱讲讲前端的一些'分层'案例:
Virtual DOM¶
前端石器时代,我们页面交互和渲染,是通过服务端渲染或者直接操作DOM实现的, 有点像C/C++这类系统编程语言手动操纵内存. 那时候JQuery很火:

后来随着软硬件性能越来越好、Web应用也越来越复杂,前端开发者的生产力也要跟上,类似JQuery这种命令式的编程方式无疑是比较低效的. 尽管手动操作 DOM 可能可以达到更高的性能和灵活性,但是这样对大部分开发者来说太低效了,我们是可以接受牺牲一点性能换取更高的开发效率的.
怎么解决,再加一层吧,后来React就搞了一层VirtualDOM。我们可以声明式、组合式地构建一颗对象树, 然后交由React将它映射到DOM:
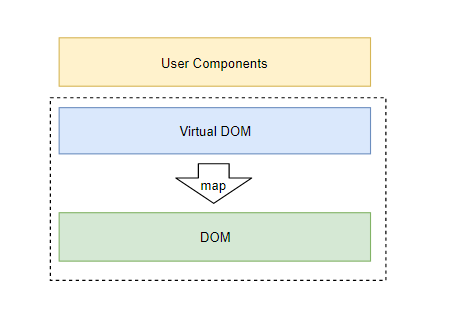
一开始VirtualDOM和DOM的关系比较暧昧,两者是耦合在一起的。后面有人想,我们有了VirtualDOM这个抽象层,那应该能多搞点别的,比如渲染到移动端原生组件、PDF、Canvas、终端UI等等。
后来VirtualDOM进行了更彻底的分层,有着这个抽象层我们可以将VirtualDOM映射到更多类似应用场景:
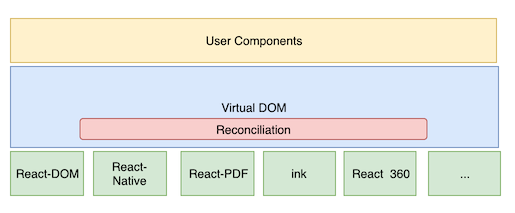
所以说 VirtualDOM 更大的意义在于开发方式的转变: 声明式、 数据驱动, 让开发者不需要关心 DOM 的操作细节(属性操作、事件绑定、DOM 节点变更),换句话说应用的开发方式变成了view=f(state), 这对生产力的解放是有很大推动作用的; 另外有了VirtualDOM这一层抽象层,使得多平台渲染成为可能。
当然VirtualDOM或者React,不是唯一,也不是第一个这样的解决方案。其他前端框架,例如Vue、Angular基本都是这样一个发展历程。
上面说了,分层不是银弹。我们通过ReactNative可以开发跨平台的移动应用,但是众所周知,它运行效率或者灵活性暂时是无法与原生应用比拟的。
Taro¶
Taro 和React一样也采用分层架构风格,只不过他们解决的问题是相反的。React加上一个分层,可以渲染到不同的视图形态;而Taro则是为了统一多样的视图形态: 国内现如今市面上端的形态多种多样,Web、React-Native、微信小程序...... 针对不同的端去编写多套代码的成本非常高,这种需求催生了Taro这类框架的诞生. 使用 Taro,我们可以只书写一套代码, 通过编译工具可以输出到不同的端:
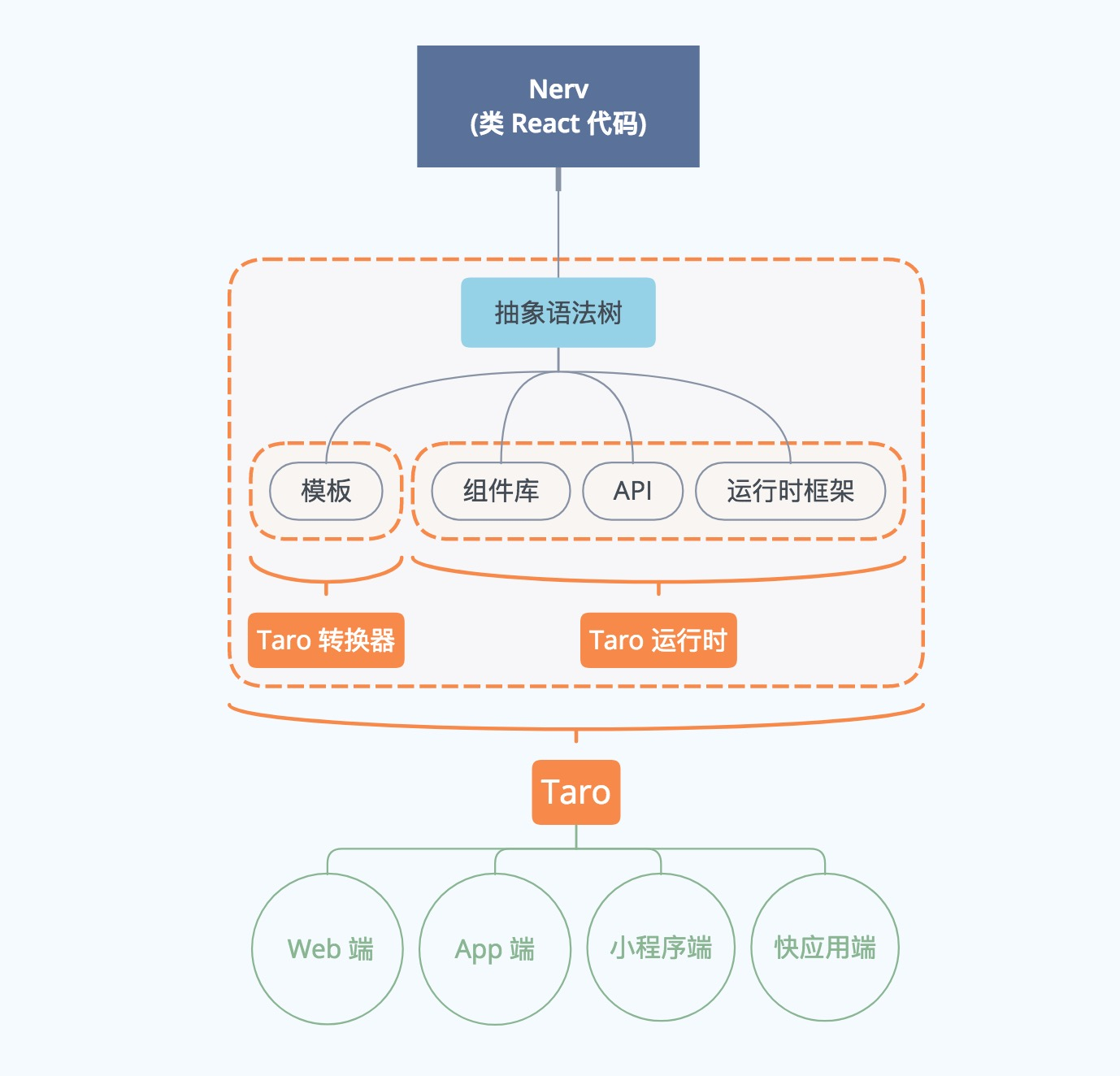
(图片来源: 多端统一开发框架 - Taro)
管道和过滤器¶
在管道/过滤器架构风格中,每个组件都有一组输入和输出,每个组件职责都很单一, 数据输入组件,经过内部处理,然后将处理过的数据输出。所以这些组件也称为过滤器,连接器按照业务需求将组件连接起来,其形状就像‘管道’一样,这种架构风格由此得名。
这里面最经典的案例是*unix Shell命令,Unix的哲学就是“只做一件事,把它做好”,所以我们常用的Unix命令功能都非常单一,但是Unix Shell还有一件法宝就是管道,通过管道我们可以将命令通过标准输入输出串联起来实现复杂的功能:
# 获取网页,并进行拼写检查。代码来源于wiki
curl "http://en.wikipedia.org/wiki/Pipeline_(Unix)" | \
sed 's/[^a-zA-Z ]/ /g' | \
tr 'A-Z ' 'a-z\n' | \
grep '[a-z]' | \
sort -u | \
comm -23 - /usr/share/dict/words | \
less
另一个和Unix管道相似的例子是ReactiveX, 例如RxJS. 很多教程将Rx比喻成河流,这个河流的开头就是一个事件源,这个事件源按照一定的频率发布事件。Rx真正强大的其实是它的操作符,有了这些操作符,你可以对这条河流做一切可以做的事情,例如分流、节流、建大坝、转换、统计、合并、产生河流的河流......
这些操作符和Unix的命令一样,职责都很单一,只干好一件事情。但我们管道将它们组合起来的时候,就迸发了无限的能力.
import { fromEvent } from 'rxjs';
import { throttleTime, map, scan } from 'rxjs/operators';
fromEvent(document, 'click')
.pipe(
throttleTime(1000),
map(event => event.clientX),
scan((count, clientX) => count + clientX, 0)
)
.subscribe(count => console.log(count));
除了上述的RxJS,管道模式在前端领域也有很多应用,主要集中在前端工程化领域。例如'老牌'的项目构建工具Gulp, Gulp使用管道化模式来处理各种文件类型,管道中的每一个步骤称为Transpiler(转译器), 它们以 NodeJS 的Stream 作为输入输出。整个过程高效而简单。
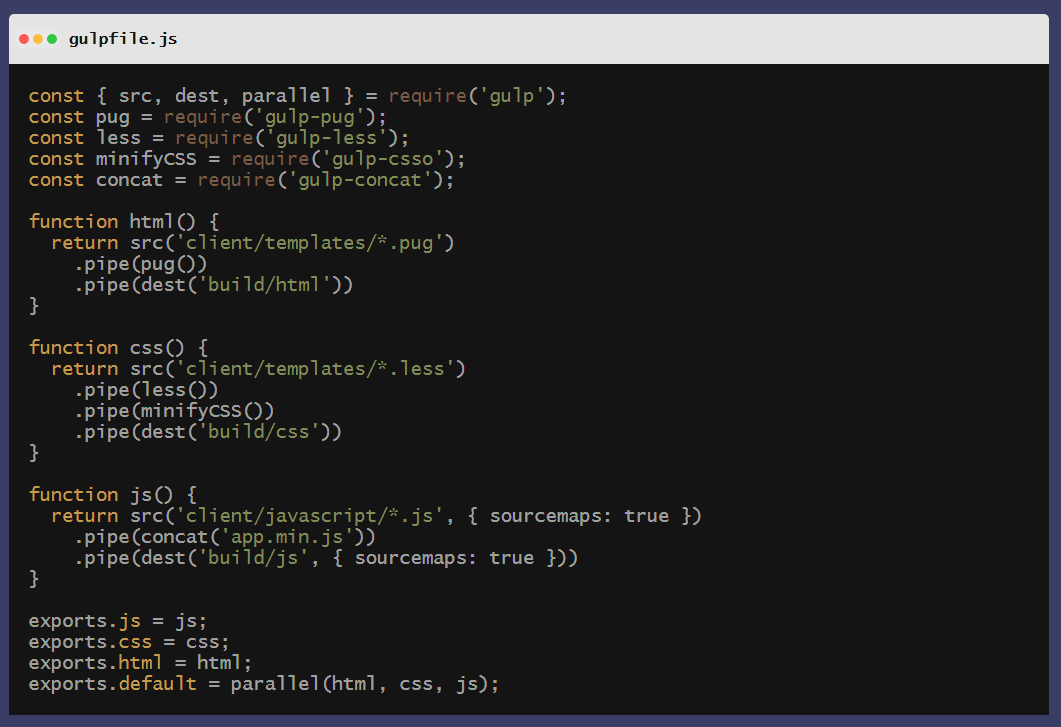
不确定是否受到Gulp的影响,现代的Webpack打包工具,也使用同样的模式来实现对文件的处理, 即Loader, Loader 用于对模块的源代码进行转换, 通过Loader的组合,可以实现复杂的文件转译需求.
// webpack.config.js
module.exports = {
...
module: {
rules: [{
test: /\.scss$/,
use: [{
loader: "style-loader" // 将 JS 字符串生成为 style 节点
}, {
loader: "css-loader" // 将 CSS 转化成 CommonJS 模块
}, {
loader: "sass-loader" // 将 Sass 编译成 CSS
}]
}]
}
};
中间件(Middleware)¶
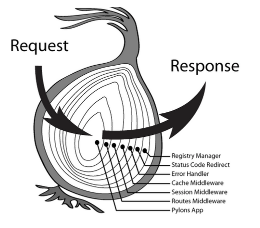
如果开发过Express、Koa或者Redux, 你可能会发现中间件模式和上述的管道模式有一定的相似性,如上图。相比管道,中间件模式可以使用一个洋葱剖面来形容。但和管道相比,一般的中间件实现有以下特点:
- 中间件没有显式的输入输出。这些中间件之间通常通过集中式的上下文对象来共享状态
- 有一个循环的过程。管道中,数据处理完毕后交给下游了,后面就不管了。而中间件还有一个回归的过程,当下游处理完毕后会进行回溯,所以有机会干预下游的处理结果。
我在谷歌上搜了老半天中间件,对于中间件都没有得到一个令我满意的定义. 暂且把它当作一个特殊形式的管道模式吧。这种模式通常用于后端,它可以干净地分离出请求的不同阶段,也就是分离关注点。比如我们可以创建这些中间件:
- 日志: 记录开始时间 ⏸ 计算响应时间,输出请求日志
- 认证: 验证用户是否登录
- 授权: 验证用户是否有执行该操作的权限
- 缓存: 是否有缓存结果,有的话就直接返回 ⏸ 当下游响应完成后,再判断一下响应是否可以被缓存
- 执行: 执行实际的请求处理 ⏸ 响应
有了中间件之后,我们不需要在每个响应处理方法中都包含这些逻辑,关注好自己该做的事情。下面是Koa的示例代码:
const Koa = require('koa');
const app = new Koa();
// logger
app.use(async (ctx, next) => {
await next();
const rt = ctx.response.get('X-Response-Time');
console.log(`${ctx.method} ${ctx.url} - ${rt}`);
});
// x-response-time
app.use(async (ctx, next) => {
const start = Date.now();
await next();
const ms = Date.now() - start;
ctx.set('X-Response-Time', `${ms}ms`);
});
// response
app.use(async ctx => {
ctx.body = 'Hello World';
});
app.listen(3000);
事件驱动¶
事件驱动, 或者称为发布-订阅风格, 对于前端开发来说是再熟悉不过的概念了. 它**定义了一种一对多的依赖关系**, 在事件驱动系统风格中,组件不直接调用另一个组件,而是触发或广播一个或多个事件。系统中的其他组件在一个或多个事件中注册。当一个事件被触发,系统会自动通知在这个事件中注册的所有组件.
这样就**分离了关注点,订阅者依赖于事件而不是依赖于发布者,发布者也不需要关心订阅者,两者解除了耦合**。
生活中也有很多发布-订阅的例子,比如微信公众号信息订阅,当新增一个订阅者的时候,发布者并不需要作出任何调整,同样发布者调整的时候也不会影响到订阅者,只要协议没有变化。我们可以发现,发布者和订阅者之间其实是一种弱化的动态的关联关系。
解除耦合目的是一方面, 另一方面也可能由基因决定的,一些事情天然就不适合或不支持用同步的方式去调用,或者这些行为是异步触发的。
JavaScript的基因决定事件驱动模式在前端领域的广泛使用. 在浏览器和Node中的JavaScript是如何工作的? 可视化解释 简单介绍了Javascript的执行原理,其中提到JavaScript是单线程的编程语言,为了应对各种实际的应用场景,一个线程以压根忙不过来的,事件驱动的异步方式是JavaScript的救命稻草.
浏览器方面,浏览器就是一个GUI程序,GUI程序是一个循环(更专业的名字是事件循环),接收用户输入,程序处理然后反馈到页面,再接收用户输入... 用户的输入是异步,将用户输入抽象为事件是最简洁、自然、灵活的方式。
需要注意的是:事件驱动和异步是不能划等号的。异步 !== 事件驱动,事件驱动 !== 异步
扩展:
- 响应式编程
- 响应式编程本质上也是事件驱动的,下面是前端领域比较流行的两种响应式模式:
函数响应式(Functional Reactive Programming), 典型代表RxJS-
透明的函数响应式编程(Transparently applying Functional Reactive Programming - TFRP), 典型代表Vue、Mobx -
消息总线:指接收、发送消息的软件系统。消息基于一组已知的格式,以便系统无需知道实际接收者就能互相通信
MV*¶
MV*架构风格应用也非常广泛。我觉MV*本质上也是一种分层架构,一样强调职责分离。其中最为经典的是MVC架构风格,除此之外还有各种衍生风格,例如MVP、MVVM、MVI(Model View Intent). 还有有点关联Flux或者Redux模式。
家喻户晓的MVC¶
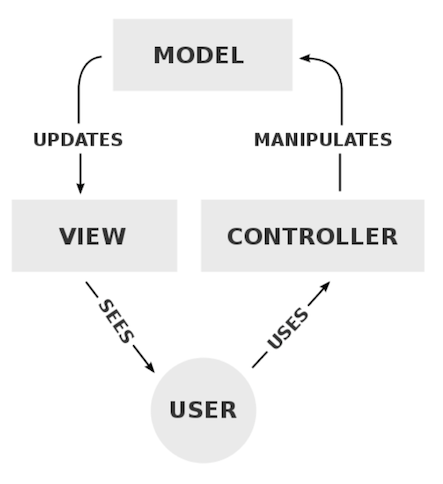
如其名,MVC将应用分为三层,分别是:
- 视图层(View) 呈现数据给用户
- 控制器(Controller) 模型和视图之间的纽带,起到不同层的组织作用:
- 处理事件并作出响应。一般事件有用户的行为(比如用户点击、客户端请求),模型层的变更
- 控制程序的流程。根据请求选择适当的模型进行处理,然后选择适当的视图进行渲染,最后呈现给用户
- 模型(Model) 封装与应用程序的业务逻辑相关的数据以及对数据的处理方法, 通常它需要和数据持久化层进行通信
目前前端应用很少有纯粹使用MVC的,要么视图层混合了控制器层,要么就是模型和控制器混合,或者干脆就没有所谓的控制器. 但一点可以确定的是,很多应用都不约而同分离了'逻辑层'和'视图层'。
下面是典型的AngularJS代码, 视图层:
<h2>Todo</h2>
<div ng-controller="TodoListController as todoList">
<span>{{todoList.remaining()}} of {{todoList.todos.length}} remaining</span>
[ <a href="" ng-click="todoList.archive()">archive</a> ]
<ul class="unstyled">
<li ng-repeat="todo in todoList.todos">
<label class="checkbox">
<input type="checkbox" ng-model="todo.done">
<span class="done-{{todo.done}}">{{todo.text}}</span>
</label>
</li>
</ul>
<form ng-submit="todoList.addTodo()">
<input type="text" ng-model="todoList.todoText" size="30"
placeholder="add new todo here">
<input class="btn-primary" type="submit" value="add">
</form>
</div>
逻辑层:
angular.module('todoApp', [])
.controller('TodoListController', function() {
var todoList = this;
todoList.todos = [
{text:'learn AngularJS', done:true},
{text:'build an AngularJS app', done:false}];
todoList.addTodo = function() {
todoList.todos.push({text:todoList.todoText, done:false});
todoList.todoText = '';
};
todoList.remaining = function() {
var count = 0;
angular.forEach(todoList.todos, function(todo) {
count += todo.done ? 0 : 1;
});
return count;
};
todoList.archive = function() {
var oldTodos = todoList.todos;
todoList.todos = [];
angular.forEach(oldTodos, function(todo) {
if (!todo.done) todoList.todos.push(todo);
});
};
});
至于MVP、MVVM,这些MVC模式的延展或者升级,网上都大量的资源,这里就不予赘述。
Redux¶
Redux是Flux架构的改进、融合了Elm语言中函数式的思想. 下面是Redux的架构图:
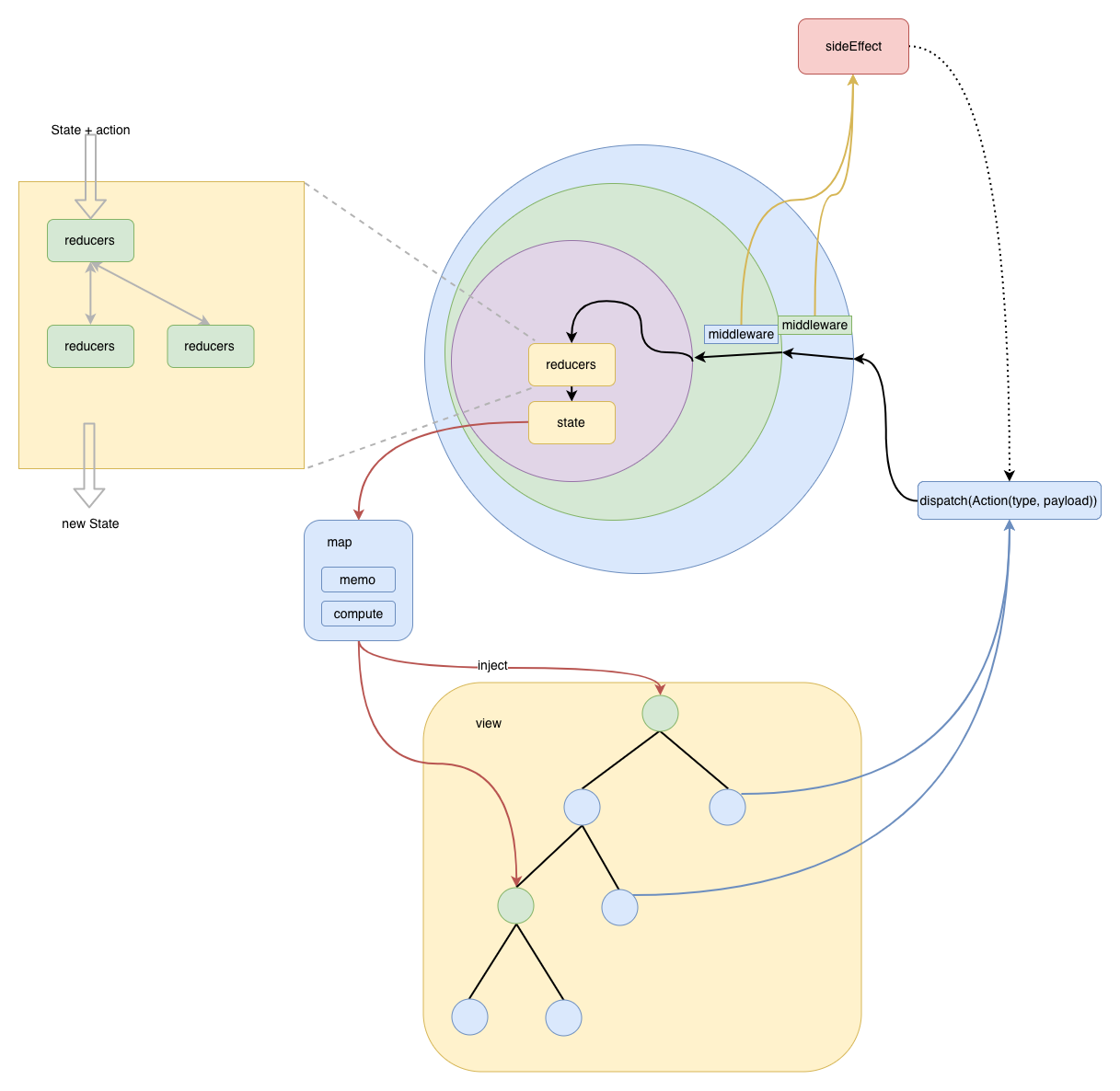
从上图可以看出Redux架构有以下要点:
- 单一的数据源.
- 单向的数据流.
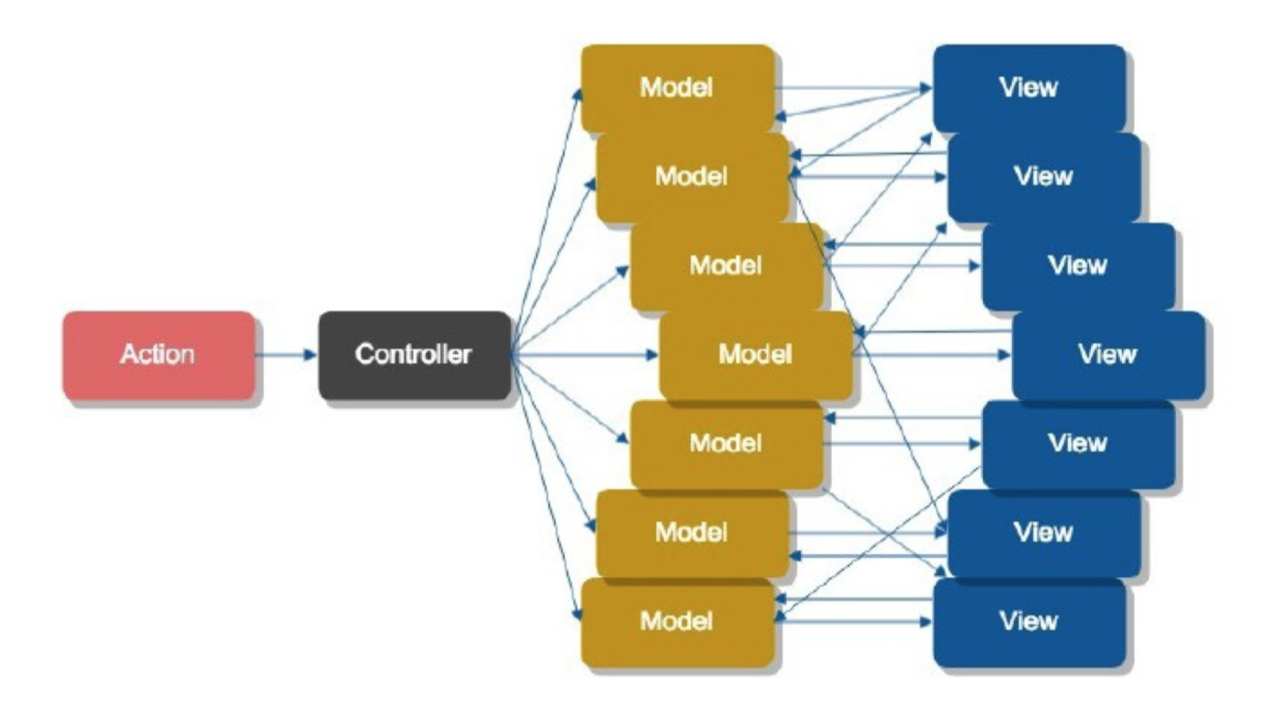
单一数据源, 首先解决的是传统MVC架构多模型数据流混乱问题(如下图)。单一的数据源可以让应用的状态可预测和可被调试。另外单一数据源也方便做数据镜像,实现撤销/重做,数据持久化等等功能
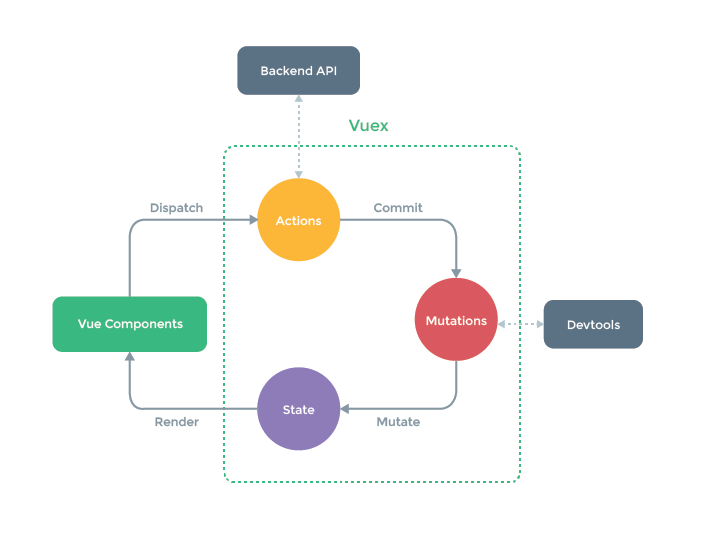
单向数据流用于辅助单一数据源, 主要目的是阻止应用代码直接修改数据源,这样一方面简化数据流,同样也让应用状态变化变得可预测。
上面两个特点是Redux架构风格的核心,至于Redux还强调不可变数据、利用中间件封装副作用、范式化状态树,只是一种最佳实践。还有许多类Redux的框架,例如Vuex、ngrx,在架构思想层次是一致的:
复制风格¶

基于复制(Replication)风格的系统,会利用多个实例提供相同的服务,来改善服务的可访问性和可伸缩性,以及性能。这种架构风格可以改善用户可察觉的性能,简单服务响应的延迟。
这种风格在后端用得比较多,举前端比较熟悉的例子,NodeJS. NodeJS是单线程的,为了利用多核资源,NodeJS标准库提供了一个cluster模块,它可以根据CPU数创建多个Worker进程,这些Worker进程可以共享一个服务器端口,对外提供同质的服务, Master进程会根据一定的策略将资源分配给Worker:
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
// Fork workers.
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`);
});
} else {
// Workers可以共享任意的TCP连接
// 比如共享HTTP服务器
http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world\n');
}).listen(8000);
console.log(`Worker ${process.pid} started`);
}
利用多核能力可以提升应用的性能和可靠性。我们也可以利用PM2这样的进程管理工具,来简化Node集群的管理,它支持很多有用的特性,例如集群节点重启、日志归集、性能监视等。
复制风格常用于网络服务器。浏览器和Node都有Worker的概念,但是一般都只推荐在CPU密集型的场景使用它们,因为浏览器或者NodeJS内置的异步操作已经非常高效。实际上前端应用CPU密集型场景并不多,或者目前阶段不是特别实用。除此之外你还要权衡进程间通信的效率、Worker管理复杂度、异常处理等事情。
有一个典型的CPU密集型的场景,即源文件转译. 典型的例子是CodeSandbox, 它就是利用浏览器的Worker机制来提高源文件的转译性能的:
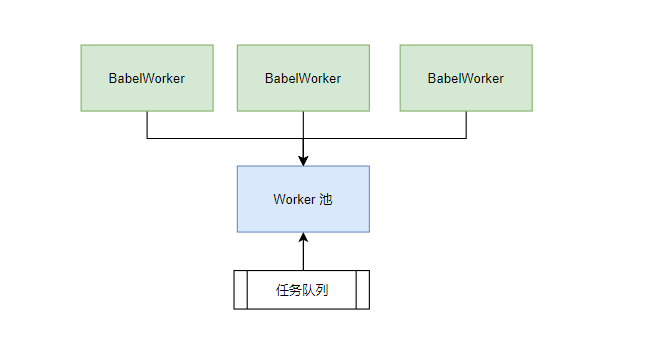
除了处理CPU密集型任务,对于浏览器来说,Worker也是一个重要的安全机制,用于隔离不安全代码的执行,或者限制访问浏览器DOM相关的东西。小程序抽离逻辑进程的原因之一就是安全性
其他示例:
- ServerLess
微内核架构¶
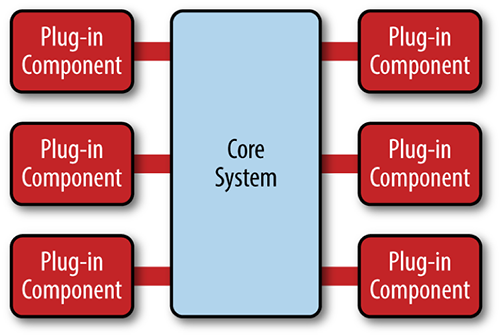
微内核架构(MicroKernel)又称为"插件架构", 指的是软件的内核相对较小,主要功能和业务逻辑都通过插件形式实现。内核只包含系统运行的最小功能。插件之间相互独立,插件之间的通信,应该降到最低,减少相互依赖。
微内核结构的难点在于建立一套粒度合适的插件协议、以及对插件之间进行适当的隔离和解耦。从而才能保证良好的扩展性、灵活性和可迁移性。
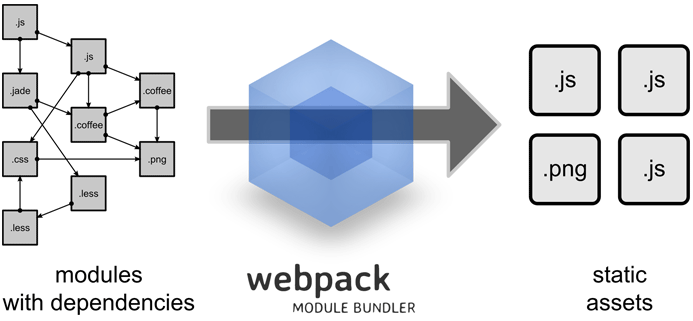
前端领域比较典型的例子是Webpack、Babel、PostCSS以及ESLint, 这些应用需要应对复杂的定制需求,而且这些需求时刻在变,只有微内核架构才能保证灵活和可扩展性。
以Webpack为例。Webpack的核心是一个Compiler,这个Compiler主要功能是集成插件系统、维护模块对象图, 对于模块代码具体编译工作、模块的打包、优化、分析、聚合统统都是基于外部插件完成的.
如上文说的Loader运用了管道模式,负责对源文件进行转译;那Plugin则可以将行为注入到Compiler运行的整个生命周期的钩子中, 完全访问Compiler的当前状态。
Sean Larkin有个演讲: Everything is a plugin! Mastering webpack from the inside out
这里还有一篇文章<微内核架构应用研究>专门写了前端微内核架构模式的一些应用,推荐阅读一下。
微前端¶
前几天听了代码时间上左耳朵耗子的一期节目, 他介绍得了亚马逊内部有很多小团队,亚马逊网站上一块豆腐块大小的区域可能是一个团队在维护,比如地址选择器、购物车、运达时间计算... 大厂的这种超级项目是怎么协调和维护的呢? 这也许就是微前端或者微服务出现的原因吧。
微前端旨在将单体前端分解成更小、更简单的模块,这些模块可以被独立的团队进行开发、测试和部署,最后再组合成一个大型的整体。
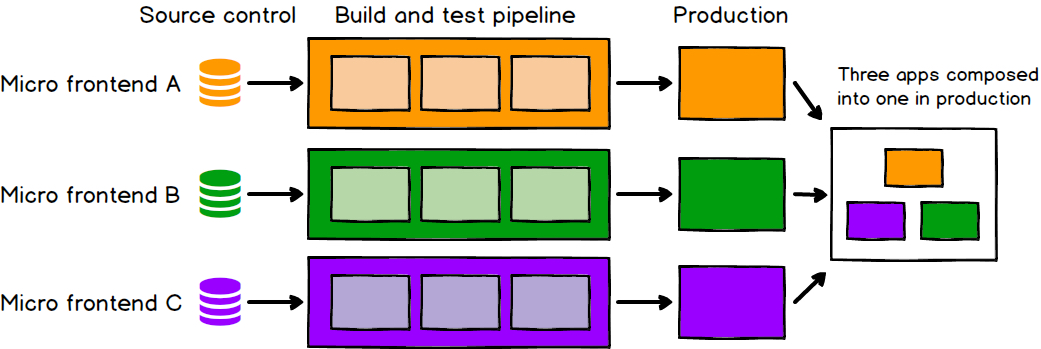
微前端下各个应用模块是独立运行、独立开发、独立部署的,相对应的会配备更加自治的团队(一个团队干好一件事情)。 微前端的实施还需要有稳固的前端基础设施和研发体系的支撑。
如果你想深入学习微前端架构,建议阅读Phodal的相关文章,还有他的新书《前端架构:从入门到微前端》
组件化架构¶
组件化开发对现在的我们来说如此自然,就像水对鱼一样。 以致于我们忘了组件化也是一种非常重要的架构思想,它的中心思想就是分而治之。按照Wiki上面的定义是:组件化就是基于可复用目的,将一个大的软件系统按照分离关注点的形式,拆分成多个独立的组件,主要目的就是减少耦合.
从前端的角度具体来讲,如下图,石器时代开发方式(右侧), 组件时代(左侧):
(图片来源: www.alloyteam.com/2015/11/we-…)
按照Vue官网的说法: 组件系统是 Vue 的另一个重要概念,因为它是一种抽象,允许我们使用小型、独立和通常可复用的组件构建大型应用。仔细想想,几乎任意类型的应用界面都可以抽象为一个组件树:
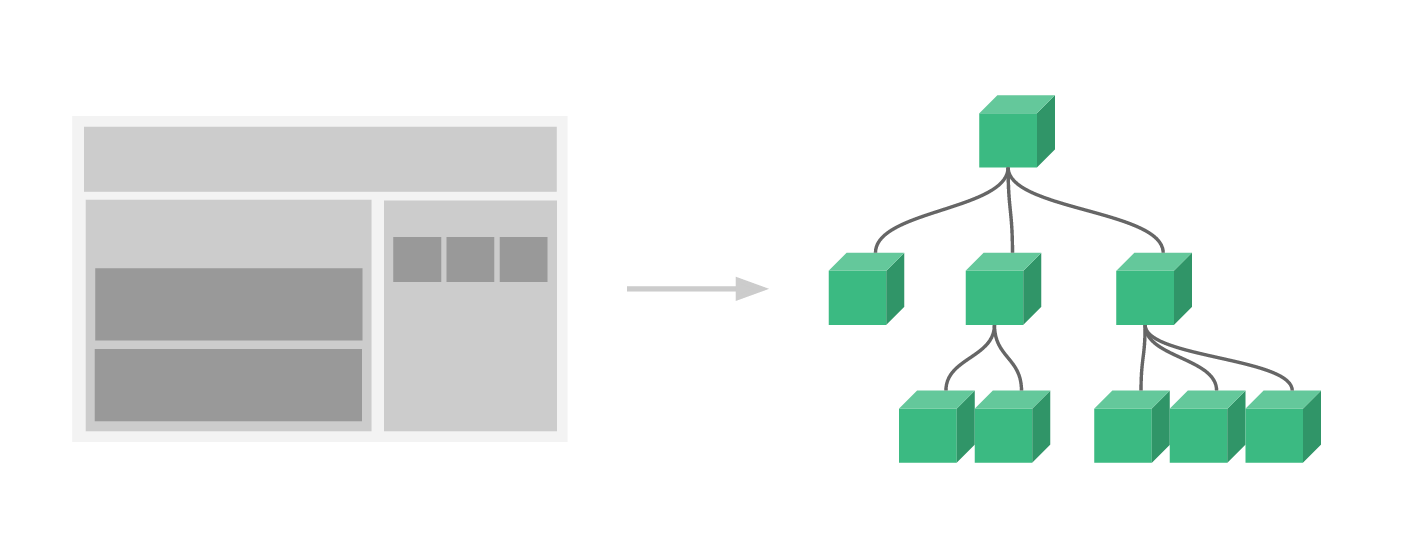
按照我的理解**组件跟函数是一样的东西,这就是为什么函数式编程思想在React中会应用的如此自然**。若干个简单函数,可以复合成复杂的函数,复杂的函数再复合成复杂的应用。对于前端来说,页面也是这么来的,一个复杂的页面就是有不同粒度的组件复合而成的。
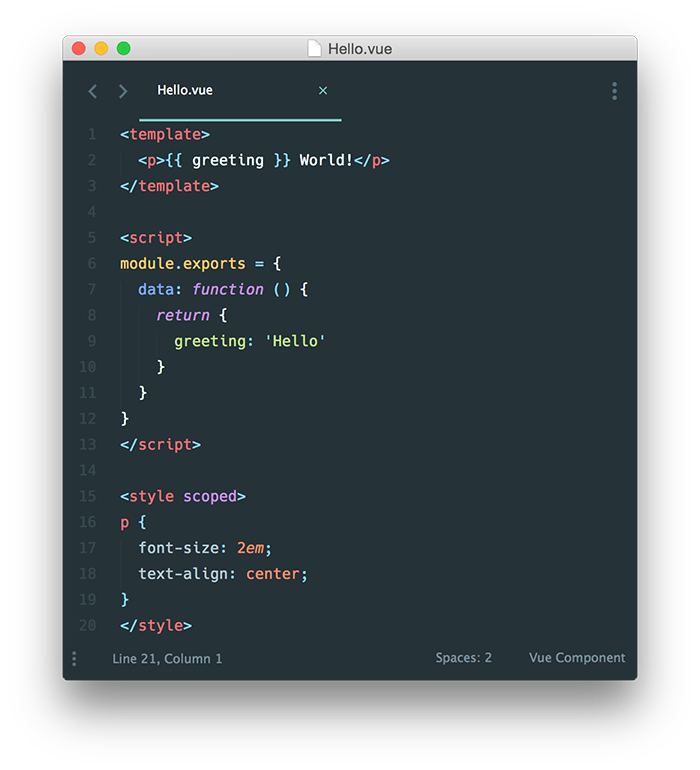
组件另外一个重要的特征就是**内聚性**,它是一个独立的单元,自包含了所有需要的资源。例如一个前端组件较包含样式、视图结构、组件逻辑:
其他¶
我终于编不下去了!还有很多架构风格,限于文章篇幅, 且这些风格主要应用于后端领域,这里就不一一阐述了。你可以通过扩展阅读了解这些模式
- 面向对象风格: 将应用或系统任务分割为单独、可复用、可自给的对象,每个对象都包含数据、以及对象相关的行为
- C/S 客户端/服务器风格
- 面向服务架构(SOA): 指那些利用契约和消息将功能暴露为服务、消费功能服务的应用
- N层/三层: 和分层架构差不多,侧重物理层. 例如C/S风格就是一个典型的N层架构
- 点对点风格
通过上文,你估计会觉得架构风格比设计模式或者算法好理解多的,正所谓‘大道至简’,但是‘简洁而不简单’!大部分项目的架构不是一开始就是这样的,它们可能经过长期的迭代,踩着巨人的肩膀,一路走过来才成为今天的样子。
希望本文可以给你一点启发,对于我们前端工程师来说,不应该只追求能做多酷的页面、掌握多少API,要学会通过现象看本质,举一反三融会贯通,这才是进阶之道。
文章有错误之处,请评论指出
本文完!